
こんにちは!データサイエンス室(以下、DS室)の山本です(@__Y4M4MOTO__)です。
先日1/30(木)に開催された「みんなの考えた最強のデータアーキテクチャ〜2025もやってきましょうSP!」に表題のタイトルで登壇させていただきました!
この記事では、登壇してみてのレポートを記していきます。
各種資料
私の登壇資料
配信アーカイブ
Xポストまとめ
みん強に応募しようと思ったきっかけ
2023年に弊社のテックカンファレンス「Yappli Tech Conference 2023」に「次の10年を戦える分析用データ基盤構築の第一歩 - dbtによる基盤刷新とクエリ費用90%削減への取り組み -」という題で登壇しました。発表内容の中で、個人的に「あえてDWH層(データウェアハウス層)を作らず、1テーブル1クエリで集計するようにした」という部分に面白さを感じたのが発端です。
面白さを感じた理由は以下の通りです。
- 「DWH層を作らないメリット」というのを初めて知った
- 「社内でちょっとデータ活用進んでいてーー」という規模感ではなく、「プロダクトとしてしっかり取り組む必要があり、さらに扱うデータもアプリの操作ログという膨大なもの」という大きな規模感で実施している
これまでデータエンジニアリング系のイベントに参加してきて、このような事例に出会ったことがなかったので、どこかで喋ってみたいなと思っていました。
その後、昨年11月にこちらの投稿を見かけました。みん強は過去に試聴参加したことがあり、参加者の多さと内容の濃さに驚いたことがあったので、「これはチャンスでは…?」と思い、応募しました(と、言いつつ応募するにあたって色々な方に「このネタで面白いかな…?」という相談はさせていただいてました。相談に乗っていただいた方々、本当にありがとうございました…!🙇)。
みん強'25参加登録数200名近くになってキテます🙌
— みっつ (@kaz3284) 2024年11月8日
ありがとうございます😃
ただ、発表者応募が現在1件のみです💦(受付期間は来週一杯)
身近の開発現場話しのご応募お待ちします🙏https://t.co/DJYmWpOOwJ
みんなの考えた最強のデータアーキテクチャ〜2025もやってきましょうSP!…
なお、最終的に14件の応募があり2倍以上の倍率となっていたので、その中から今回選んでいただけたのは本当に光栄でした…!
資料を作成してみての感想
「どういう結論で発表を締めるか?」で非常に悩みました…。
「弊社のデータ基盤の成長過程を述べて、最後に総括する」という流れ自体はすぐに決まったのですが、総括してみたところ、下記のような結論になってしまいました。
- データ利用者を軸にSmall start, Quick winでデータ基盤を育成する
- 早すぎる共通化・最適化を避ける
これらは過去に多くの方が何度も言及してきた、いわば「当たり前のこと」です。ただそれを述べるだけでは、聞き手が「それはもう分かっていて…」と感じ、学びの薄い発表になってしまうかもしれないと思いました。
そこで、これら「当たり前のこと」を実践するために何が重要かを自分なりに言語化することで、学びのある発表にしようと考えました。言語化作業難しかったですが、その甲斐あってか共感の声をたくさんいただけてとても嬉しかったです!
#みん強
— pei (@pei0804) 2025年1月30日
わかりみしかない。そんな戦略的にやれたら困らない。 pic.twitter.com/Ak6Ge1evdN
#みん強
— yuichi | データエンジニア (@1210yuichi0) 2025年1月30日
わかりみ、すぐ共通化したくなっちゃう自分を殴りたい pic.twitter.com/kI0F7TOp7q
特に「早すぎる共通化・最適化を避けよう(誘惑に耐える)」の部分が共感されていたように思います。ここの部分は、自分が今絶賛、共通化・最適化の部分で苦しんでいて、自戒も込めて言語化した部分でもあります。「後から共通化・最適化した方が楽」と言っていますが、実際はやっぱり言うほど楽ではないです…。ですので、作業をしていて「なんでこここんなことになってるんだ…?最初から良い感じにしておけば良かったのに…」と思うこともあります。ただ、今自分が触れているデータ基盤は共通化・最適化に工数を割く価値があると判断されるほど使われているものです。そもそも、そのフェーズに到達できなければ先を見据えた共通化・最適化はすべて無駄になってしまいます。このスライドは「そこを履き違えてはいけない」という自戒を込めたスライドでした。
共感の声の中に「とはいえ大まかにロードマップは作っておいた方が良い」という意見もありました。この点、発表内ではあまり触れられませんでしたが、実はDS室内で今回の登壇資料をレビューした際に議論となった部分でした。今回、我々がロードマップ無しでもなんとかなったのは、「内製基盤:立ち上げ期」に入社した弊社一人目のデータ人材である阿部(@abe_masatoshi)が、過去に複数社のデータ基盤構築を経験し、豊富な知識を持っていたことが大きかったと思います。
すごい共感でしかない。
— muguruma (@mt_musyu) 2025年1月30日
ただ、大まかでもいいからロードマップは作っていた方が良い派ではある。ステークホルダーの理解を得るのも大事なので・・・
#みん強 pic.twitter.com/ju2VRxaavS
資料作成にあたって既存の文献や資料を色々読んだのですが、その中でも特に次の資料が参考になったので紹介させていただきます(ありがとうございました…!🙏)
- 実践的データ基盤への処方箋 〜ビジネス価値創出のためのデータ・システム・ヒトのノウハウ:書籍案内|技術評論社
- 使われないものを作るな!出口から作るデータ分析基盤 / Data Platform Development Starting from the User Needs - Speaker Deck
登壇してみての感想
登壇自体も非常に良い経験になったのですが、パネルディスカッションの面白さが個人的に一番良かったです。各々が持っている経験則や哲学を語り合うことでより深い言語化・抽象化が行われていく感じが非常に面白かったです。
各お題で個人的に面白かったところを下記にまとめます。
お題①「データ基盤を開発する上で避けていること」
- サイロ化を恐れすぎること。サイロ化を恐れて何でも共通化してしまうとかえって誰も使わないデータ基盤になってしまうかもしれないため。
↓
- サイロはあるのが普通。繋げるとメリットがあるのに繋げられてないところがサイロとして認識される。
- 「サイロ化を恐れすぎない」というのは「これはサイロではない(=今やることではない)ということを確認する」こと。
お題②「ツールや技術選定において『ずっと使い続けるつもり』と『将来的に変えうる』の線引きをどう考えるか」
- 将来的に全部変わるという前提で、導入時から別ツールへの移行のしやすさを意識しておくことが大事。
- 「ずっと使い続ける」=ロックインのリスクがある。
お題③「規模(基盤、組織、事業)が5倍に増える見込みがあると仮定したら、あなたはこれから1年何をする?」
- ボトルネックを探す。1→10→100とスケールしていくとボトルネックは移動し続けるので、それを探し続ける。探し方はエンドユーザから上流へ辿っていくと見つけやすい。
お題(視聴者投稿)「RevOps進めるためには結論いろんな部署メンバーの協力がないとなかなか進まないと思うのですが、どう立ち回るとうまくいくのでしょう」
- ただ困りごとを見つけて解消していくだけだと局所最適になってしまうかもなので、「ここを良くするとここも良くなるはず」という全体感も意識することが大事。
アフタートーク①「データの民主化ってどうなの?」
- 「データを民主化すること」は「データをフルオープンにすること」ではない
- データ利用者のリテラシーに合わせて提供するBIツールの自由度を変えるのが良さそう(原理的にはどれでも同じデータが出せる。違うのは自由度だけ)
アフタートーク②「AI活用」
- 正解が分かってる問題じゃないとまだ今のAIでは解けないので、そういった問題をどう見つけて落とし込むかが重要
- 人間に「良い感じにして」と頼む場合でも「良い感じってどういう感じ?」といった情報を与えないとうまくいかないので、AIに対しても同じように情報を与える必要がある
- なので、与える情報が揃っていることが大事(意思決定の際に議事録を残しているか?など)
おまけ: 地味な個人的WIN
私の発表で言った「Small start, Quick win」というフレーズがMCのゲンシュンさんに刺さったようで、その後何回も使っていただいていたのが個人的に嬉しかったです…!
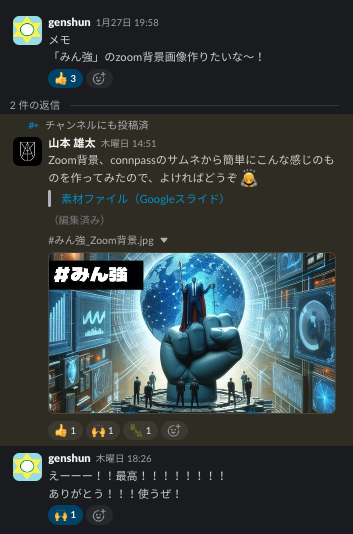
また、司会のお二人が使っていたZoom背景は、私がサクッと作ってお渡ししたものだったりします。司会・登壇者での事前打ち合わせの際に「作りたいね」という話が出ていたので作りました。すごく喜んで使っていただけて、こちらも嬉しかったです…!
まとめ
この記事では「#みん強」の登壇レポートを記しました。非常に面白く学びの多いイベントでしたので、登壇しようか迷っている方がおられたらぜひチャレンジしてみることをお勧めします!
ここまでお読みいただきありがとうございました🙇