自己紹介
初めまして!東京理科大学大学院修士1年の鬼頭勇輝と申します。
今までデータ分析のインターンを経験してきましたが、今回ヤプリのデータサイエンス室での2ヶ月のインターンで、初めてデータ基盤という領域に足を踏み入れました。
2ヶ月間、データの「分析」だけでなく「基盤」に触れる中で、私のデータに対するものの見方は180度変わりました。
今回の記事では、その驚きと、データ基盤構築業務を通じて得た自分の中の新たな視点を、皆さんにお伝えできたら嬉しいです!
ヤプリのインターンに惹かれた理由
今までデータ分析のインターンを経験してきましたが、常に感じていた課題がありました。それは、「整備されたデータ」を「活用する」ところからしか関われないという点です。目の前のデータがどこから来て、どのように加工され、どれほどの信頼性を持っているのか、そのデータの裏側の部分がいつも見えていませんでした。
分析タスクをこなすたびに、データ抽出に多くの時間がかかることに、もどかしさを感じていました。
そんな中、、たまたま応募の機会があったヤプリのデータサイエンス室のインターンでは、私がこれまで触れることのなかった「データ基盤構築」という領域に挑戦できることを知りました。
「整備されたデータを使う」立場から、「信頼できるデータを生み出す」立場へ。
データ基盤構築という新しい経験が、自分のデータに対する視野を広げ、データサイエンティストとしての新たな視点を与えてくれると確信し、今回のインターンに応募しました。
インターンタスク:データ基盤の改善
YA(Yappli Analytics)とCMSレポート
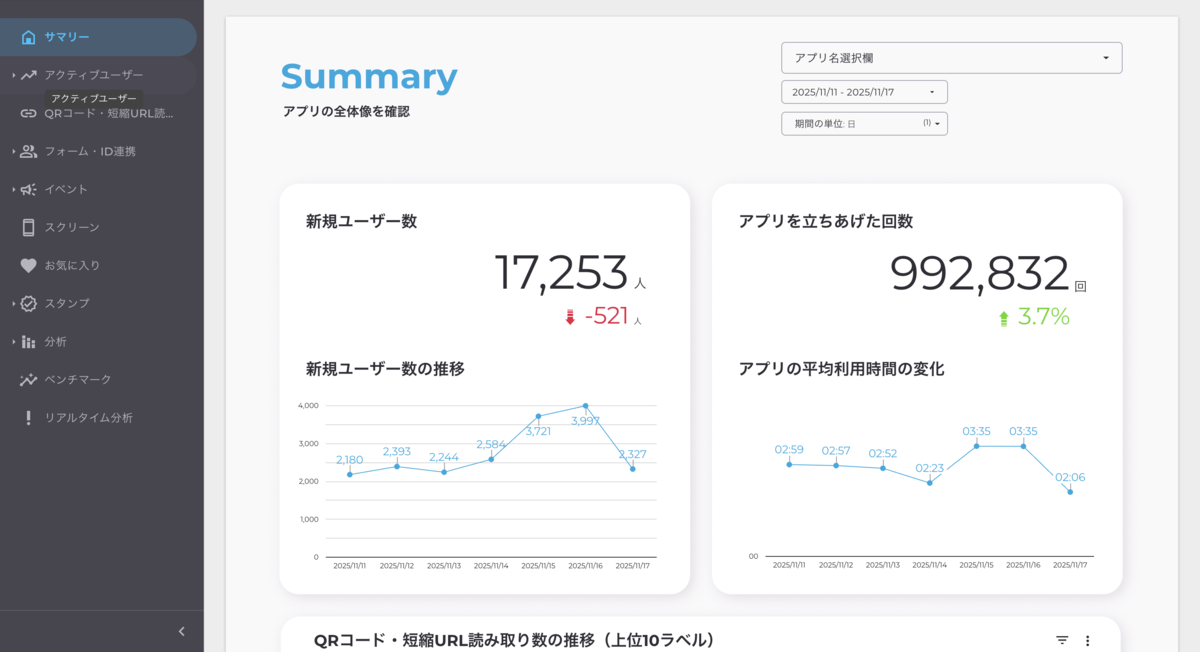
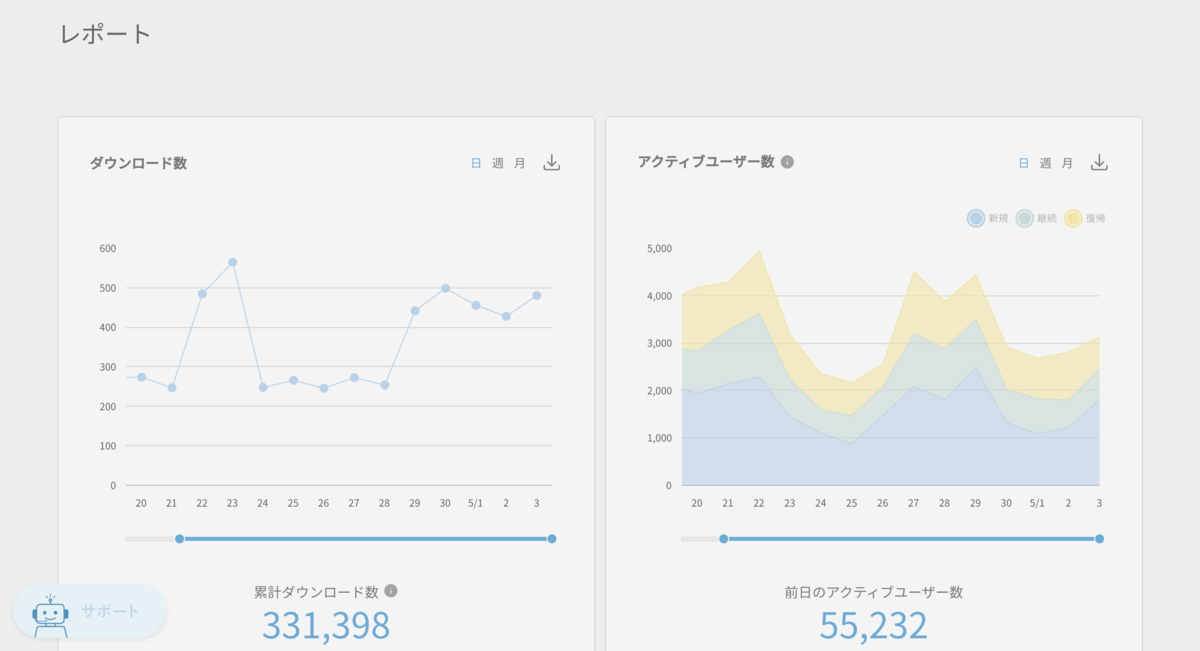
Yappliを使ってのプラットフォームでスマホアプリを作成した顧客は、スマホアプリに訪れたユーザーの数などさまざまな情報を確認する必要があります。そのためのツールとしてヤプリでは、「Yappli Analytics(以下、YA)」というアナリティクスツールとYappli管理画面にレポート画面(以下、CMSレポート)を用意しています。
現状の課題とインターンで取り組んだこと
現状、CMSレポートでしか見れず、YAでは見れないデータがいくつか存在しています。これに対し、顧客から「都度両方のツールで確認するのに手間がかかる」という声がありました。そこでインターンでは、CMSレポートでしか見れないデータの1つである「QRコード読み取り数」について、YAでも見れるようにしました。
「QRコード読み取り数」のデータとは、スマホアプリをストアからインストールするためにQRコードを読み取った際のデータです。CMSレポートでは、この読み取り数の推移をグラフで表示しています。
タスクに取り組むにあたって学んだ前提知識
上記のデータ基盤を構築するタスクを取り組むにあたって、データエンジニアリングやdbtについて教えていただきました。特に学びとなった資料は以下です。
システム設計
CMSレポートで表示しているデータは、1つのクエリで生データから集計結果まで出力する仕組みになっていました。今回のタスクでは、上記で学んだデータエンジニアリングの作法に則り、「ロジックの分離・共通化」も含めてYAで表示するデータの集計処理をdbtで実装しました。
ヤプリのdbt環境ではstaging層/component層/出力層の3層で構成されているので、この層分けと読みやすいSQL文を意識して、次の6ステップで実装を進めていきました。
- 出力層にある CMSの「QRコード・短縮URL読み取り数」をグラフ化するテーブルからcomponent層でやるべきロジックを切り出してcomponent層におく
- 1で切り出してcomponent層に配置したロジックを使って出力層にある CMSの「QRコード・短縮URL読み取り数」の示すテーブルを修正する
- 1で切り出してcomponent層に配置したロジックを使ってYA用のQRコード・短縮URL読み取り数テーブルを出力層で作成
- 一連で作ったテーブルを本番反映
- 3の出力層でYA用に作ったQRコード・短縮URL読み取り数テーブルをもとにLooker Studio上でQRコード・短縮URL読み取り数のグラフを作成
- CSの方にフィードバックをいただき、Looker Studioの本番反映
このプロセスを通じて、ロジックの一元管理と再利用を行いました。

各実装での苦労した点と乗り越えたこと
component層でやるべきロジックへの切り出し
「component層でやるべきロジックへの切り出し」では、次の2点で苦労しました。
出力層にある CMSの「QRコード・短縮URL読み取り数」をどのように論理ロジックでまとまりを作るか
私は、コードを実際に見て各※CTE(共通テーブル式:SQL内で一時的に定義し、再利用可能なテーブル)の依存関係を地道に確認しました。また、GeminiなどのAIアシスタントにコードを渡し、全体構造から見て何が行われているかという役割を教えてもらいながら、具体と抽象を行き来することで、再利用可能な論理ロジックの単位を特定していきました。
どこまでのロジックのまとまりをcomponent層に入れるべきか
component層は汎用ロジックを担うため、過度に特化したロジックを入れてしまうと、将来的に再利用性が失われてしまいます。これは、データエンジニアとしての経験と知識が大きく問われる領域でした。 そこで私は、長年の経験を持つ先輩エンジニアに積極的にアドバイスをいただき、どこの論理的なロジックのまとまりをcomponent層に入れるべきか決めました。
YA用のQRコード・短縮URL読み取り数テーブルを出力層で作成
ここでは、「Looker Studioの可視化に適したデータ形式でテーブルを作成する」という点に苦労しました。
YAのダッシュボードはLooker Studioで構築されますが、このLooker Studioと、既存のCMSの機能には大きな違いがあります。このため、元のCMS用の出力層のSQLをベースにYA用に修正する際、「Looker Studioでは不要なデータ」を最終テーブルから排除する必要がありました。単純にロジックを共通化するだけでなく、最終的なツールに合わせてテーブルを作成しなければなりませんでした。
そこで、Looker Studioで図表を沢山作成したり、Looker Studioの説明しているサイトを徹底的に読んだりしました。その上でYA用のグラフを作成して、データサイエンス室の方からフィードバックをいただき、CMS向けには必要だった「欠損値を0埋めする」や「期間特定」を担うCTEを削除し、Looker Studio側で柔軟に計算できるシンプルな形にデータを削ぎ落とすことで、Looker Studioのためのテーブル作成を実現しました。
GitHub上のコメント
GitHub上でレビューを受ける際、「自分がどのような変更を行ったのか」、そして「変更後のデータが元のデータと論理的に一致しているのか」を分かりやすく説明することに、非常に苦労しました。 私はよく主語を抜く癖があったので、しっかり主語述語・文脈を意識してわかりやすく時間をかけて論理的に分かりやすいコメントを付けるように徹底しました。
まとめと今後の展望
取り組んでみての感想
本案件を無事に本番反映し、顧客への提供まで完了することができました。

技術的な課題を乗り越えた達成感はもちろんですが、何よりも嬉しかったのはお客様からのフィードバックです。
今回の改善に対して、社内からは「お客様へのレポートやYAの説明が格段に楽になった」という声を頂きました。また、この図表きっかけでお客さまから「アプリの状態把握ができ、ヤプリに乗り換えて良かった」という声を頂くこともあったそうです。データ基盤構築が、最終的にお客様の満足度に直結した瞬間を体験でき、すごく喜びを感じています。

自分の今後のキャリア
インターン前、私は「データ分析」というスキルを極めることが重要だと考えていました。しかし、今回のインターンを通して、データ分析の裏側にあるデータ基盤がいかに重要かを初めて知りました。
データ基盤は普段は見えにくい場所にあるものの、データ分析やプロダクトの機能といった全てを支える屋台骨のような存在です。今では、データ基盤がしっかり設計されて信頼性が担保されていなければ、その上で行われるどんな高度なデータ分析もいずれは崩れてしまうと確信しています。
データエンジニアリングを通じて、データの信頼性を生み出すことこそが、データ活用において最も根源的で重要な仕事であるという視点を得ました。 こうした視点を活かし、今後はデータ基盤の構築から実装、さらにビジネスへの展開まで全てを網羅できる人材になりたいという、キャリア像も描けました。
最後に
この貴重な学びを与えてくださったヤプリの皆様に心より感謝申し上げます。 本当に今までご指導いただきましたデータサイエンス室の皆さん、そして進路についてアドバイスいただきました他のヤプリ社員の皆様に深く感謝いたします!本当にありがとうございました!
ヤプリではデータサイエンス室へのインターンを募集しております!本記事を読んで興味を持っていただけましたらぜひご応募ください!🙌