こんにちは、サーバーサイドグループのマネージャーの鬼木です。
弊社ではAPMとしてNew Relicを導入、活用しています。調査時のログ検索やAPMの確認以外にも、追加したapplicationのアラートを作成するなどサーバーサイドエンジニアもNew Relicを活用しています。
今回は、New Relicのアラート作成時に使用するAlert condition内の設定項目である「Streaming method」について紹介します。この設定項目を使用することでより信頼性の高いEvent集計、アラート検知を行うことができますが、正しく理解していないと期待通りのアラート検知ができないこともあるため、注意が必要となります。そこで、今回は「Streaming method」の詳細とその利点、注意点について解説します。
Alert condition
Streaming methodについて紹介する前に、Streaming methodを内包し、アラートに関する設定を定義するAlert conditionについて説明します。
Alert conditionではアラートをトリガーするためのルールや基準を設定します。NRQL(New Relic Query Language)を使用して条件にマッチしたEventデータに対して集計を行い、定義した閾値を超えていればアラートを出す等の設定が可能です。例えば以下のAlert conditionは特定の認証サービスで10分間で「invalid status code 403」を含むエラーログが1件以上あればアラートを通知する、といった設定になります。
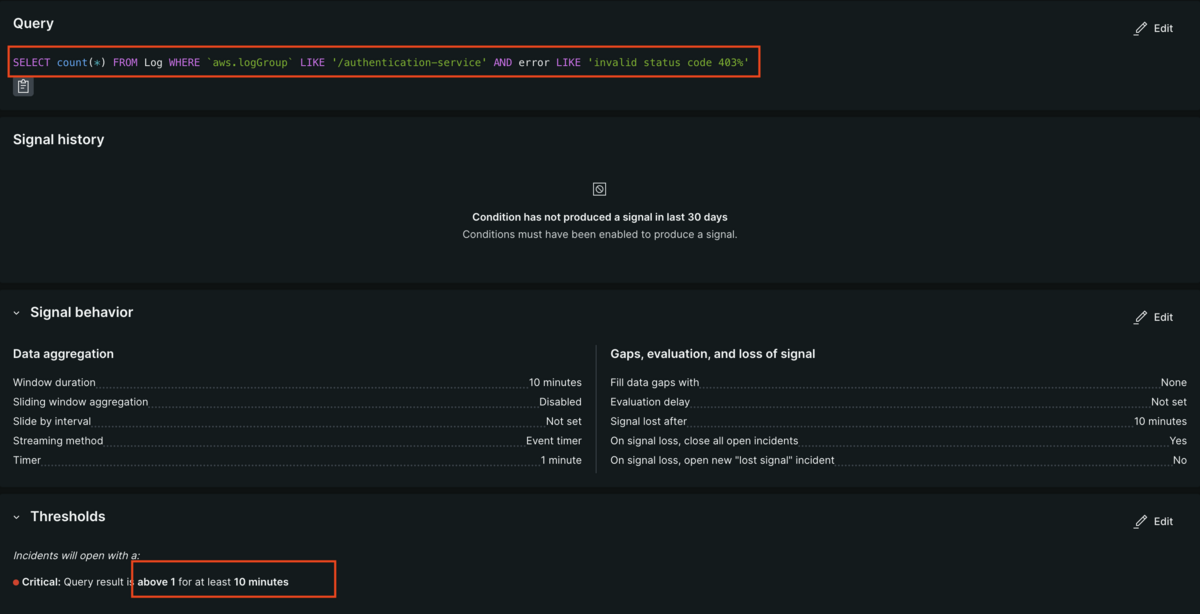
Alert conditionで設定した条件に合致するデータがNew Relicに到着してからインシデントがトリガーされるまでのプロセスは以下のようになっています。

- ログやメトリクスなどのデータのストリーミング
- NRQLクエリのWHERE句で条件に合致したデータのみを後続に送る
- Aggregation window(下記で説明)にデータを集計する(この集計をどのように行うか定義するのが今回紹介するStreaming methodになります)
- 一定時間経過後に集計を完了し、Alert conditionで定義した閾値を超えているか判定する
- 閾値を超えていれば、アラートが通知される ※1
※1 厳密にはAlert conditionでインシデントがトリガーされ、それをAlert conditionに紐づくAlert policyがハンドリングします。Alert policyに通知先(Slackチャンネルなど)を設定し、Alert conditionで設定した閾値を超えたときに設定された通知先に通知する形で弊社では設定を行なっています。
Aggregation window
Aggregation windowはデータの集計と処理のために使用される特定の時間範囲を指します。例えばAggregation windowを10分に設定することで、10分間隔ごとの単位で対象となるEventの件数が集計され、その件数がXX件以上だったらアラートをトリガーするかといった設定を行うことができます。数秒など非常に短い範囲だとノイズを無視できないため平滑化を行うなど、適切なAggregation windowを設定することで信頼性の高いアラートを設定できます。
例)Aggregation windowを3分で設定し、該当のデータが1件以上だった場合にアラート通知を行う設定の場合、以下のように条件にマッチするEventの件数が1件以上で閾値(赤線のCritical threshould)を超えており、かつアラートがOpenになっていない場合にアラートがトリガーされます。

Streaming methodとは
ここからが今回の記事の本題になります。 Streaming methodは、データをストリーミングして集計、判定を行う方法についての定義になります。一見リアルタイムで流れてくるStreaming dataを溜めて閾値判定してるだけのように見えますが、applicationでの実際にログ出力が行われてからNew Relicに到達するまでのタイムラグや、applicationの障害時にログがNew Relic側に送られないといったケースなども考慮された処理方法が提供されています。
Streaming methodには3つの種類があり、各処理方法でデータの集計方法が異なります。
- Event timer
- Event flow
- Cadence
このうち3のCadenceは古いストリーミング方法であり、現在はEvent timerかEvent flowの利用が推奨されているため、今回はEvent timerとEvent flowについて紹介します。
Event timer
Event timerはEvent flowに比べてシンプルなStreaming methodです。
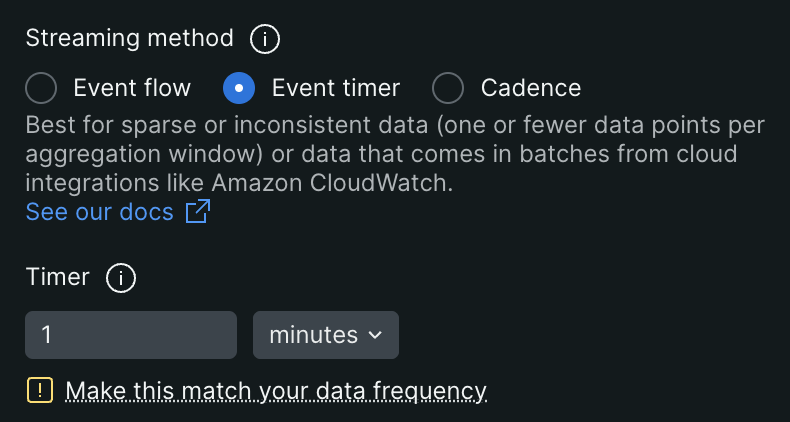
設定項目には「Timer」があり、Eventが到着してからどれくらいの期間集計を行うかを定義します。
例えば、Window Duration(Aggregation Windowの時間): 5分、Timer: 5分の場合、以下の挙動になります。

10:31:最初のEvent到着、集計開始(この時点では集計は10:36に完了予定)
10:32:最後のEvent到着、Timerはリセットされ、完了予定は10:37に更新される
10:37:その後新しいEventが到着しなかったため、10:37に10:30 - 10:35のWindowの集計が完了する
Timerを設定する背景には、applicationでログが出力されてからNew Relicに到達するまでの遅延を考慮することがあります。例えば、環境要因で10:36に10:34に出力されたログが到達する場合もあります。Timerの設定により、こうした遅延をカバーできます。
このような特徴を持つEvent Timerには注意点もあります。障害などでEventが送られない、または遅延が発生する場合、Eventが集計から漏れる可能性があります。例えば、10:33からapplicationで障害が起こり、10:37までに10:33-35のEventが到着しなかった場合、それらのEventはAggregation Windowに含まれず、期待した集計結果とならない可能性があります。
Event Timerを設定すると上記のような挙動となるため、Event Timerは頻度の低いエラーログなど、batch処理や1件のエラーログでもクリティカルになるようなapplicationのEventのデータ集計に適しています。
Event flow
Event Flowは、Event Timer以上に信頼性や正確性の高い集計を行うことができます。
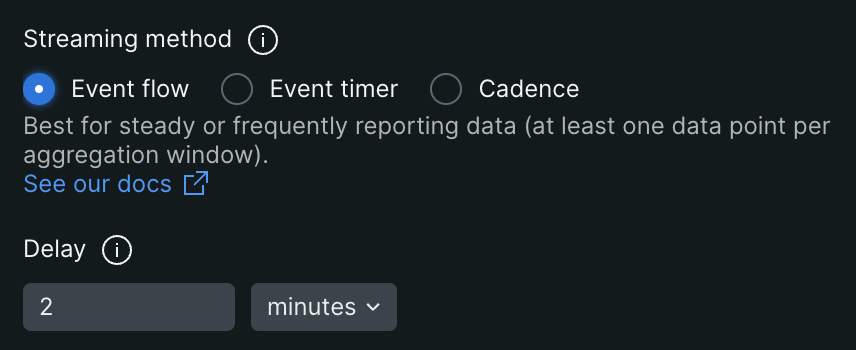
設定項目には「Delay」があり、Aggregation Windowの終点からDelayで設定した期間以降に最初のEventが到達したら、Aggregation Windowの集計を完了します。
例えば、Window Duration(Aggregation Windowの時間): 10分、Delay: 5分の場合、以下の挙動になります。

14:20 - 14:35:該当のAggregation Windowのデータが連続的に到着(14:30-14:35の間にも遅延して到着する14:20 - 14:30のデータが入ってくる可能性がある)
14:35:Aggregation Windowの終点+Delay(5分)後の14:35のデータが到達すると、14:20 - 14:30のAggregation Windowの集計を行う
Event Flowの特徴は、連続的にEventが到着する場合に高い信頼性や正確性を担保できる点です。例えば、applicationで障害が起こり、その影響で14:27からEventの到着が途切れたとしても、14:20-14:30までのAggregation Windowは完了せず、復旧して14:35のデータが到着してから集計が行われるため、Eventの取り逃しが起きにくいStreaming methodです。
ただし、Aggregation Windowの終点+Delayで設定した期間後の最初のEventが到達しない限り、Aggregation Windowの集計は完了しません。例えば、Event自体が少ないapplicationのケースで、14:25のEventが到着したものの、次のEventが1時間後に到着した場合、Aggregation Windowの集計は完了せず、アラート検知が遅れる可能性があります(今回このStreaming methodについて調べたきっかけは、eventの少ないbatch処理のalert検知が期待通りの挙動をせず調査したところ、Streaming methodをEvent flowに設定していたことが原因だと分かったことからでした)。
このような特徴を持つため、Event flowは常に一定のアクセスが来るapplicationのwarn、error log監視など、頻繁かつ順番に到着するデータ集計に適しています。
まとめ
Event Timer
- 最新のデータが到着してから「Timer」後に集計が行われるため、Eventが少なく閾値が低い場合に有用
- 障害などでeventが送られてない、eventの遅延が発生するなどケースがある場合、eventが集計から漏れる可能性がある
Event Flow
- Aggregation Windowの終点+Delay後の最初のデータが到着してから集計が行われるため、大量のEventが継続的かつ順番に送られる場合に有用
- 障害起因など、データの遅延が発生する場合も正しく集計できる可能性が高い
- Eventが少ない場合、意図した集計ができないケースがある
最後に
ヤプリでは今年も引き続きサーバーサイドエンジニアを募集しています。興味を持った方、是非カジュアル面談にお越しください!