こんにちは!データサイエンス室(以下、DS室)の山本です(@__Y4M4MOTO__)です。
BigQueryにおいて複数のGoogle Cloudプロジェクト(以下、GCプロジェクト)に存在するテーブルの参照状況をINFORMATION_SCHEMAから調査し、Looker Studioでダッシュボード化してみたので、その内容を記載します。
背景
この取り組みは、主に以下の2つの目的から始まりました。
- 不要なテーブルの特定と削除: 長期間参照されていないテーブルを特定し、整理することで、データ管理の効率化を図ります。
- テーブル参照元の把握と移行支援: どのテーブルがどこから参照されているかを明確にし、参照元の切り替え作業(特にdbtへの移行)をスムーズに進めることを目指します。
背景として、弊社では2023年からデータパイプラインのdbt移行プロジェクトを推進しています。以前はTROCCOを利用して共通データマートを作成していましたが、現在はdbtモデルへの移行を進めており、プロダクトで利用するデータマートの参照元切り替えは完了しました。
残る課題として、Looker、Looker Studio、スプレッドシートといったBIツールや各種レポートからの参照元切り替えがあり、そのために各テーブルの参照状況を正確に把握する必要がありました。
方法
BigQueryでテーブルの参照状況を調査する一般的な方法として、INFORMATION_SCHEMAを利用する方法があります。
具体的には、JOBSビューの referenced_tables カラムを参照することで、各クエリでどのテーブルを参照したかを確認できます。
しかし、この方法だけでは「一度も参照されていないテーブル」を特定することは困難です。そこで、TABLESビューを活用します。TABLESビューからプロジェクト内の全テーブル一覧を取得し、そのテーブルがJOBSビューの referenced_tables カラムに一度も現れない場合、それは直近で参照されていない可能性が高いと判断できます。
さらに、弊社では複数のGCプロジェクトを運用しているため、単一のプロジェクトに対するクエリだけでは全体の参照状況を把握できません。そこで、参照状況を確認したい複数のGCプロジェクトのINFORMATION_SCHEMAをUNION ALLで結合することで、複数のプロジェクトを横断的に調査できるよう工夫しました。
今回実施した方法の全体像は以下の通りです。
- TABLESビューからのテーブル一覧作成: 各GCプロジェクトのINFORMATION_SCHEMA.TABLESから必要な情報を抽出し、UNION ALLで結合して全プロジェクトのテーブル一覧を作成します。
- JOBSビューとの結合による参照状況の集計: 作成したテーブル一覧と各GCプロジェクトのINFORMATION_SCHEMA.JOBSを結合し、
referenced_tablesカラムの情報に基づいて各テーブルの参照状況を集計します。
この集計結果をLooker Studioでダッシュボード化することで、不要なテーブルの特定や、参照元の把握を簡単にできるようにしました。
STEP 1|TABLESビューからのテーブル一覧作成
テーブル一覧は、テーブル参照状況を知りたいGCプロジェクトのINFORMATION_SCHEMA.TABLESをUNION ALLを用いて結合し、作成します。
table_list AS ( SELECT table_catalog AS project_id, table_schema AS dataset_name, table_name, table_type, creation_time AS table_creation_time, FROM ( SELECT * FROM `YOUR_GC_PROJECT_1_ID`.`region-YOUR_REGION`.INFORMATION_SCHEMA.TABLES UNION ALL SELECT * FROM `YOUR_GC_PROJECT_2_ID`.`region-YOUR_REGION`.INFORMATION_SCHEMA.TABLES UNION ALL ... ) ),
ただ、このままだとシャーディングテーブルが全て別テーブルとして認識されてしまって扱いづらいので、1つのテーブルとして扱えるようまとめます。弊社の場合、Google Analyticsからエクスポートしたテーブルがシャーディングテーブルになっていたので、次のようなクエリを書いて1つにまとめました。
-- シャーディングテーブルを除いたテーブル一覧 table_list_others AS ( SELECT * FROM table_list WHERE -- シャーディングテーブルを除外 NOT ( project_id = "YOUR_GC_PROJECT_ID" AND dataset_name = "YOUR_DATASET_NAME" AND table_name LIKE "ga_sessions_20%" ) ), -- ”ga_sessions_*”系のシャーディングテーブルを1テーブルにまとめる table_list_ga_sessions AS ( SELECT project_id, dataset_name, "ga_sessions_*" AS table_name, table_type, MIN(table_creation_time) AS table_creation_time, -- テーブル作成日時は最も古いものを採用 FROM table_list WHERE -- ga_sessions_*系のシャーディングテーブルを抽出 project_id = "YOUR_GC_PROJECT_ID" AND dataset_name = "YOUR_DATASET_NAME" AND table_name LIKE "ga_sessions_20%" GROUP BY 1,2,3,4 ), -- まとめた結果をUNION ALLで結合 final AS ( SELECT * FROM table_list_others UNION ALL SELECT * FROM table_list_ga_sessions ) SELECT * FROM final
当初は次のような方法でテーブル一覧を作成していましたが、記事執筆時に上記の方法を思いついたので変更しました。
- SCHEMATAビューでデータセット一覧を取得
- 取得したデータセット一覧を使って、データセットごとにテーブル一覧をTABLESビューから取得するクエリを作成
- 作成したクエリをSTRING_AGGで結合して1つのクエリにまとめる
- まとめたクエリをEXECUTE IMMEDIATEで実行
- 結果をテーブルに保存
📝クエリ
DECLARE query STRING; SET query = ( WITH query_list AS ( SELECT """ SELECT table_catalog AS project_id, table_schema AS dataset_name, table_name, table_type, creation_time AS table_creation_time, FROM """ || " `" || catalog_name || "." || schema_name || "`.INFORMATION_SCHEMA.TABLES" AS query FROM ( SELECT * FROM `YOUR_GC_PROJECT_1_ID`.`region-YOUR_REGION`.INFORMATION_SCHEMA.SCHEMATA UNION ALL SELECT * FROM `YOUR_GC_PROJECT_2_ID`.`region-YOUR_REGION`.INFORMATION_SCHEMA.SCHEMATA UNION ALL ... ) ), final AS ( SELECT STRING_AGG(query, "\nUNION ALL") AS query FROM query_list ) SELECT * FROM final ); EXECUTE IMMEDIATE FORMAT(""" CREATE OR REPLACE TABLE `YOUR_GC_PROJECT_ID.YOUR_DATASET_NAME.table_list` AS %s """, query) ; -- シャーディングテーブルを1行に統合 -- -- EXECUTE IMMEDIATE句内だと Invalid character '"' でエラーになってしまったので分けている CREATE OR REPLACE TABLE `YOUR_GC_PROJECT_ID.YOUR_DATASET_NAME.table_list` AS WITH table_list AS ( SELECT * FROM `YOUR_GC_PROJECT_ID.YOUR_DATASET_NAME.table_list` ), -- シャーディングテーブルを除いたテーブル一覧 table_list_others AS ( SELECT * FROM table_list WHERE -- シャーディングテーブルを除外 NOT ( project_id = "YOUR_GC_PROJECT_ID" AND dataset_name = "YOUR_DATASET_NAME" AND table_name LIKE "ga_sessions_20%" ) ), -- ”ga_sessions_*”系のシャーディングテーブルを1テーブルにまとめる table_list_ga_sessions AS ( SELECT project_id, dataset_name, "ga_sessions_*" AS table_name, table_type, MIN(table_creation_time) AS table_creation_time, -- テーブル作成日時は最も古いものを採用 FROM table_list WHERE -- ga_sessions_*系のシャーディングテーブルを抽出 project_id = "YOUR_GC_PROJECT_ID" AND dataset_name = "YOUR_DATASET_NAME" AND table_name LIKE "ga_sessions_20%" GROUP BY 1,2,3,4 ), -- まとめた結果をUNION ALLで結合 final AS ( SELECT * FROM table_list_others UNION ALL SELECT * FROM table_list_ga_sessions ) SELECT * FROM final ;
STEP 2|JOBSビューとの結合による参照状況の集計
テーブル一覧を作成したら、次はJOBSビューと結合して参照状況を集計します。今回はLooker Studioでダッシュボード化しやすいよう、次のようなビューを作って集計しました。
(information_schema_jobs_referenced_tables)] b[一度も参照されていないテーブルの一覧ビュー
(information_schema_jobs_referenced_tables_unused_table_list)] c[どのテーブルが何回参照されてるかの集計ビュー
(information_schema_jobs_referenced_tables_referenced_info)] a --> b a --> c
当初はダッシュボードをスプレッドシートで作成していました。しかし、Looker Studioのほうがドリルダウンしやすく、より便利だったため、途中でそちらに変更しました。
また、理想的にはマスタを直接Looker Studioから参照させた方が取り回しが良いです。しかし、後述するように、テーブルの除外条件(dbt基盤開発用のdev/stg環境用テーブルは除外するなど)はLooker Studioのフィルタ機能では表現が難しかったため、ビューを分けることにしました。
各ビューのクエリでやっていることは以下の通りです。
どのテーブルが何回参照されてるかのマスタ(information_schema_jobs_referenced_tables)
先ほど作成したテーブル一覧とJOBSビューとLEFT JOINすることで、一度も参照されていないテーブルの情報も載ったJOBSビューを作成します。JOINによって、一度も参照されていないテーブルはJOBSビューの job_id カラムがNULLになります。
📝ビューのクエリ
WITH -- import _jobs AS ( SELECT CASE WHEN job_id LIKE "job_%" THEN "job" WHEN job_id LIKE "bquxjob_%" THEN "bquxjob" WHEN job_id LIKE "bqjob_%" THEN "bqjob" WHEN job_id LIKE "script_job_%" THEN "script_job" WHEN job_id LIKE "scheduled_query_%" THEN "scheduled_query" WHEN job_id LIKE "sheets_dataconnector_scheduled_%" THEN "sheets_dataconnector_scheduled" WHEN job_id LIKE "sheets_dataconnector_%" THEN "sheets_dataconnector" WHEN job_id LIKE "materialized_view_refresh_%" THEN "materialized_view_refresh" ELSE job_id END AS job_usage, job_id, creation_time AS job_creation_time, DATE_TRUNC(DATE(creation_time, "Asia/Tokyo"), MONTH) AS job_creation_month, project_id AS exec_project_id, user_email, statement_type, query, referenced_tables, FROM ( SELECT * FROM `YOUR_GC_PROJECT_1_ID`.`region-YOUR_REGION`.INFORMATION_SCHEMA.JOBS_BY_PROJECT UNION ALL SELECT * FROM `YOUR_GC_PROJECT_2_ID`.`region-YOUR_REGION`.INFORMATION_SCHEMA.JOBS_BY_PROJECT ... ) WHERE DATE(creation_time, "Asia/Tokyo") > DATE_TRUNC(DATE_SUB(CURRENT_DATE("Asia/Tokyo"), INTERVAL 2 MONTH), MONTH) -- そのままだとデータ量が多すぎてクエリが重くなるので、直近2ヶ月に限定 ), table_list AS ( SELECT project_id, dataset_name AS dataset_id, table_name AS table_id, table_type, table_creation_time, FROM `YOUR_GC_PROJECT_ID.YOUR_DATASET_NAME.table_list` ), -- logical jobs AS ( SELECT job_usage, job_id, job_creation_time, job_creation_month, exec_project_id, user_email, statement_type, query, unnest_referenced_tables.project_id AS project_id, -- referenced_project_id, unnest_referenced_tables.dataset_id AS dataset_id, -- referenced_dataset_id, unnest_referenced_tables.table_id AS table_id, -- referenced_table_id, FROM _jobs, UNNEST(referenced_tables) AS unnest_referenced_tables ), final AS ( SELECT A.job_usage, A.job_id, A.job_creation_time, A.job_creation_month, A.exec_project_id, A.user_email, A.statement_type, A.query, COALESCE(A.project_id, B.project_id) AS project_id, COALESCE(A.dataset_id, B.dataset_id) AS dataset_id, COALESCE(A.table_id, B.table_id) AS table_id, B.table_type, B.table_creation_time, FROM table_list B LEFT JOIN jobs A USING(project_id, dataset_id, table_id) -- 未使用テーブルを含めたい&一時的に作成されその後削除されたテーブルを除きたいのでLFET JOIN ) -- final SELECT * FROM final
一度も参照されていないテーブルの一覧ビュー(information_schema_jobs_referenced_tables_unused_table_list)
先ほど作成したマスタをもとに、一度も参照されていないテーブルの一覧を作成します。前述の通り、一度も参照されていないテーブルかどうかは job_id カラムがNULLかどうかで判別できます。
なお、TABLESビューにはテーブルだけでなくビューも含まれているため、STEP 1で作成したテーブル一覧にも当然含まれています。一方、JOBSビューの referenced_tables カラムにはビューは入らず、そのビューが参照しているテーブルが入るようになっています。そのため、先ほど作成したマスタにおいて、ビューは参照されているかどうかによらず「どこからも参照されていない」状態になっています。これをそのまま取り扱うと混乱を招いてしまうため、 WHEREで table_type != "VIEW" を指定することで防いでいます。
また、dbt基盤開発用のdev/stg環境用テーブルは除外するようにしています。これらのテーブルは、dbtの開発用に作成されたものであり、実際のデータ分析やレポート作成には使用されていないため、参照状況を調査する必要がありません。
📝ビューのクエリ
WITH final AS ( SELECT * FROM `YOUR_GC_PROJECT_ID.YOUR_DATASET_NAME.information_schema_jobs_referenced_tables` WHERE job_id IS NULL -- 使っていないテーブルのみにする AND table_type != "VIEW" -- ビューはINFORMATION_SCHEMA.JOBSのreferenced_tablesに出てこない仕様っぽい=未使用かの判別ができないので除外 -- dbt基盤開発用のテーブルは見ても仕方ないので除外 AND -- ここにdev環境のテーブルを除外する条件を書く NOT ( ... ) AND -- ここにstg環境のテーブルを除外する条件を書く NOT ( ... ) ) SELECT * FROM final
どのテーブルが何回参照されてるかの集計ビュー(information_schema_jobs_referenced_tables_referenced_info)
先ほど作成したマスタをもとに、どのテーブルが何回参照されているかを集計します。GROUP BYを使わずウィンドウ関数を使っている理由は、Looker Studio上で下図のようにドリルダウンできるようにするためです。
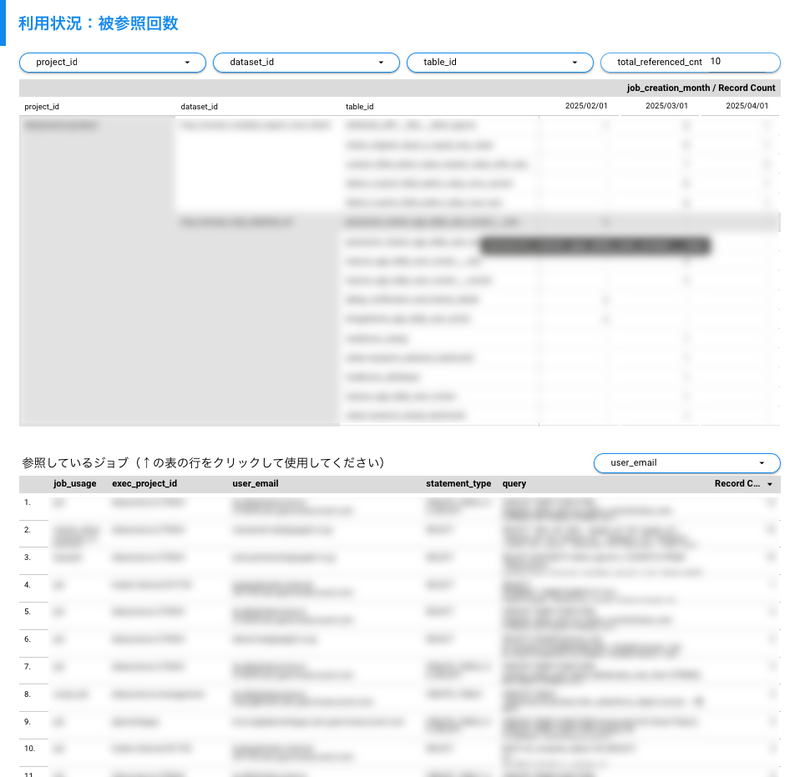
📝ビューのクエリ
WITH final AS ( SELECT *, COUNT(*) OVER(PARTITION BY project_id, dataset_id, table_id) AS total_referenced_cnt, FROM `YOUR_GC_PROJECT_ID.YOUR_DATASET_NAME.information_schema_jobs_referenced_tables` WHERE job_id IS NOT NULL -- 使っているテーブルのみにする -- dbt基盤開発用のテーブルは見ても仕方ないので除外 AND -- ここにdev環境のテーブルを除外する条件を書く NOT ( ... ) AND -- ここにstg環境のテーブルを除外する条件を書く NOT ( ... ) ) SELECT * FROM final
結び
以上のように、BigQueryのINFORMATION_SCHEMAを活用して複数プロジェクトのテーブル参照状況を調査し、Looker Studioでダッシュボード化する方法を紹介しました。テーブルの参照状況を知りたい場面は多々あるかと思いますので、その時に本記事がお役に立てれば幸いです。
ここまでお読みいただきありがとうございました🙇