1. はじめに
みなさん、こんにちは!
ヤプリでiOSエンジニアをしている白数 (@cychow_app)です。
2026/04/12 〜 2026/04/14 の期間でtry! Swift Tokyo 2026が開催されています。
Day 1では、5つのWorkshopsが開催され、それぞれ非常に興味深い内容となっていました。
私はその中の、「Enhance your apps with the Foundation Models (Foundation Modelsでアプリを強化する)」というWorkshopに参加してきました。
このWorkshopは、Appleでテクノロジーエバンジェリストを務められている3名の方が、実際にFoundation Modelsの利用方法や、on-device LLMを利用する上での注意点など、ハンズオン用のプロジェクトを用いながら説明していただくという内容でした。
参加者は、Foundation Modelsフレームワークを使用してAppleのオンデバイスLLMにアクセスするハンズオン体験を行います。本ワークショップでは、言語サポートを含むテキスト操作、ガイド付き生成、さらに、効果的なプロンプトの設計方法を探求します。そして、Foundation ModelsフレームワークをSpeechフレームワークなど機械学習のフレームワークと組み合わせる方法についても習得します。
(try! Swift Tokyo 2026 HPより)
私自身もWWDC25でFoundation Modelsが発表されたタイミングで、Xcode 26のベータ版で挙動を触ってみたりもしていましたが、今回のWorkshopではより深く、実践的な形式でのハンズオンでしたので、多くのことをインプットすることができました。
本記事はその中からいくつかピックアップし、ご紹介します。
2. Foundation Modelsとは
Workshopのハンズオンの内容がどのようなものだったのかについて入っていく前に、Foundation Modelsとは何かについて振り返っていきます。

2.1 Foundation Modelsを利用するメリット
Foundation Models は、Appleが提供している framework となっています。
Apple Intelligenceの中核にあるon-device LLMを、Swiftから直接使うためのフレームワークです。
Apple Developer Documentation では、「on-device モデルは要約、エンティティ抽出、テキスト理解、洗練、ゲーム用ダイアログ、クリエイティブコンテンツの生成など、多岐にわたるテキスト生成タスクに優れている」とも説明されています。
また、今回の Workshop 内でも、以下のような4つのメリットが得られると説明されていました。
- Private on-device:プライバシーが担保されている
- Readily available:ネットワーク環境を問わず、いつでも利用可能 (オフライン時でも利用可)
- No Cost:ローカルLLMを利用していることからコストはゼロ
- Built-in:端末のローカルLLMに App からアクセスするため、App のファイルサイズの膨大化を回避できる
2.2 Foundation Modelsの基本的な利用の流れ
Foundation Models はフレームワークのため、App に組み込むことで利用可能となります。
App 内部ではプロンプトを事前に用意しておき、on-device LLM に対して投げることで、プロンプトの回答を得られます。
ただし、基本的には on-device LLM の回答はランダムなものとなっているため、注意点も多いですが、今回のWorkshopではなるべく期待する回答がもらえるようにするためのTipsが紹介されていました。
また、音声や動画の解析など、gptモデルやclaudeモデルといったクラウド型LLMが可能なことが、ローカルLLMである Foundation Models は行えないように設計されているとも紹介されていました。
ただし、複雑な解析処理が全く行えないという訳ではなく、Foundation Models 以外の Apple が提供しているフレームワーク (ex. Vision, Speech, Speech Synthesis, Translation etc.) と組み合わせることで実現可能とのことでした。
3. ハンズオンのまとめ
3.1 ハンズオンの概要
Workshop内のハンズオンでは、その場で録音した内容の書き起こしやその要約の作成、録音内容の画像化、タイムラインの表示、録音した内容に対するQ&Aを行うといった複数の機能を持つサンプルアプリを用いて、実際に機能を部分的に実装していきながら体系的に学べるコンテンツとなっていました。
Foundation Modelsを用いることで主に要約の作成やタイムラインの作成、Q&Aといったテキストを生成する機能を実装しており、画像生成に関しては Image Playground が利用されていました。
上記の内容を下記の3つの課題に沿って、実際のソースコードを自分自身で書きながらインプットしました。
(課題3に関しては、Workshop の時間の関係で説明だけとなりました。)
- 課題1:録音内容のタイトルとイメージ画像の自動生成
- 課題2:タイムラインの抽出
- 課題3:Q&A機能の追加
本記事では、主に課題1、課題2に焦点を当ててご紹介します。
3.2 録音内容のタイトルとイメージ画像の自動生成
3.2.1 FoundationModels Framework
課題1である「録音内容のタイトルとイメージ画像の自動生成」のパートでは、Appleデバイスの on-device LLM を使用する上で最低限必要なAPI群とそれらの具体的な利用法についてみていきました。
まず、利用している端末内で on-device LLM が利用可能かを確認する必要があるため、 SystemLanguageModel.default.availability の状態に合わせて処理の分岐を追加することが推奨されています。
switch SystemLanguageModel.default.availability { case .available: ContentView() case .unavailable(.appleIntelligenceNotEnabled): UnavailableView(reason: .appleIntelligenceNotEnabled) case .unavailable(.deviceNotEligible): UnavailableView(reason: .deviceNotEligible) case .unavailable(.modelNotReady): UnavailableView(reason: .modelNotReady) case .unavailable(let other): ... }
case .available 以外は機能が利用できない趣旨をユーザーに通知するようにしましょう。
また、on-device LLM (Apple Intelligence) 利用不可時の原因は SystemLanguageModel.Availability.UnavailableReason というenumに定義されています。
| case名 | 概要 |
|---|---|
| .appleIntelligenceNotEnabled | システム設定 (設定アプリ) でApple Intelligence利用が許可されていない時 |
| .deviceNotEligible | デバイス自体がApple Intelligenceサポート外の時 |
| .modelNotReady | on-device Modelをダウンロード前あるいはダウンロード中の時 |
次に、 on-device LLM と連携するためのSessionクラスを初期化していきます。
on-device LLM とのやり取りに使用するのが、 LanguageModelSession クラスとなります。
let session = LanguageModelSession(model: SystemLanguageModel.default, instructions: "...")
上記の LanguageModelSession 初期化には、 model と instructions を指定しています。
model には、Apple Intelligence を支えるデバイス上のテキスト基盤モデルを指定することができます。
今回は default を指定しているため、テキスト基盤モデルの基本バージョンにアクセスし、汎用的なテキスト生成タスクを実行します。
続いて、instructions は、「説明書」の通りで、プロンプトに対するモデルの意図された動作を指定します。
今回はミーティングなどで録音、書き起こした内容をもとにタイトルを生成したいため、以下のような instructions が追加されていました。
let session = LanguageModelSession(model: SystemLanguageModel.default, instructions: "You are an expert headline writer who takes meeting notes and from those notes. From those notes, you must generate your best suggested title with not other text.")
上記含め、実際にタイトルの自動生成処理の内容が以下となります。
func suggestedTitle() async -> String? { let session = LanguageModelSession(model: SystemLanguageModel.default, instructions: "You are an expert headline writer who takes meeting notes and from those notes. From those notes, you MUST generate your best suggested title with not other text.") let answer = try await session.respond(to: String(text.characters), generating: RecordingTitle.self) return answer.content.title.trimmingCharacters(in: .punctuationsCharacters) }
また、generatingの型で指定している RecordingTitle もみていきます。
@Generable struct RecordingTitle { var title: String }
RecordingTitle はstructで定義されていますが、@Generable マクロが付与されています。
@Generable マクロを付与していることで、モデルがプロンプトに応じて指定の型のインスタンスを生成してくれます。
つまり、上記の answer は RecordingTitle 型のインスタンスとして生成されていることになります。
上記のように録音内容のタイトルを自動生成しましたが、Workshop 内で他にも以下の点に注意することでより確度の高い回答を得られると述べられていました。
- Instructions は基本的には英語を用いて書くのが良い。
- on-device LLM (Apple Intelligence) は 4,096 tokens しか一度に利用できない。
- 対応言語13言語のうち、日本語や中国語などは1文字1 token換算となってしまう。
- プロンプトの言語はユースケースに応じて使い分けるのが良い。
- ケースによって言語ごとの回答の精度が異なるため。
3.2.2 ImagePlayground Framework
次に録音内容のイメージ画像の自動生成です。
画像の自動生成には ImagePlayground framework を利用していきます。
ImagePlayground Framework を簡単に利用するにあたり、SwiftUIには imagePlaygroundSheet 、AppKit/UIKit には ImagePlaygroundViewController というAPIが用意されています。
ただし、今回は FoundationModels の LanguageModelSession APIと ImagePlayground の ImageCreator APIを組み合わせて画像を生成していきます。
早速、画像自動生成の処理の全体をみていきます。
func suggestedImage() async throws -> CGImage? { let session = LanguageModelSession(model: SystemLanguageModel.default, instructions: "You are a helpful assistant that takes meeting notes as input. From those notes, you MUST extract three or four terms that can be used to visualize the key concepts in the notes by using Image Playground. You MUST output only a string that can be used by Image Playground to generate an image.") let answer = try await session.respond(to: String(text.characters), generating: ImagePrompt.self) let concept = ImagePlaygroundConcept.extracted(from: answer.content.prompt) let creator = try await ImageCreator() let imageSequence = creator.images(for: [concept], style: .sketch, limit: 1) for try await image in imageSequence { return image.cgImage } return nil }
LanguageModelSessionの処理は「3.2.1 FoundationModels Framework」でも記載した通り、デバイス上のテキスト基盤モデルを利用し、画像生成のためのプロンプトテキストを生成しています。
続いて、呼び出しているのが ImagePlaygroundConcept です。
ImagePlaygroundConcept は、生成する画像に含めるコンテンツを指定する役割があります。
つまり、どのような画像を出力させたいかということです。
そして最後に呼び出しているのが、ImageCreator です。
ImageCreator は指定した説明やスタイル情報をもとに画像を生成します。
今回は style に .sketch、limit に 1 が渡されているため、手書きスケッチ風の画像が1枚生成されます。
(limitの上限値は4となっており、5枚以上の生成はシステム側によって制限されている。)
また、指定できる style 自体は、ImagePlaygroundStyle というstructに定義されており、以下となります。
| プロパティ名 | 概要 |
|---|---|
| animation | アニメーション画像を生成する |
| illustration | 2D漫画風の画像を生成する |
| sketch | 手書きのスケッチ風の画像を生成する |
| all | あらゆるスタイルで画像を作成できる |
上記のAPIを利用することで、比較的簡単に Apple デバイス上の on-device LLM を利用して、テキストや画像を生成することが可能となっています。
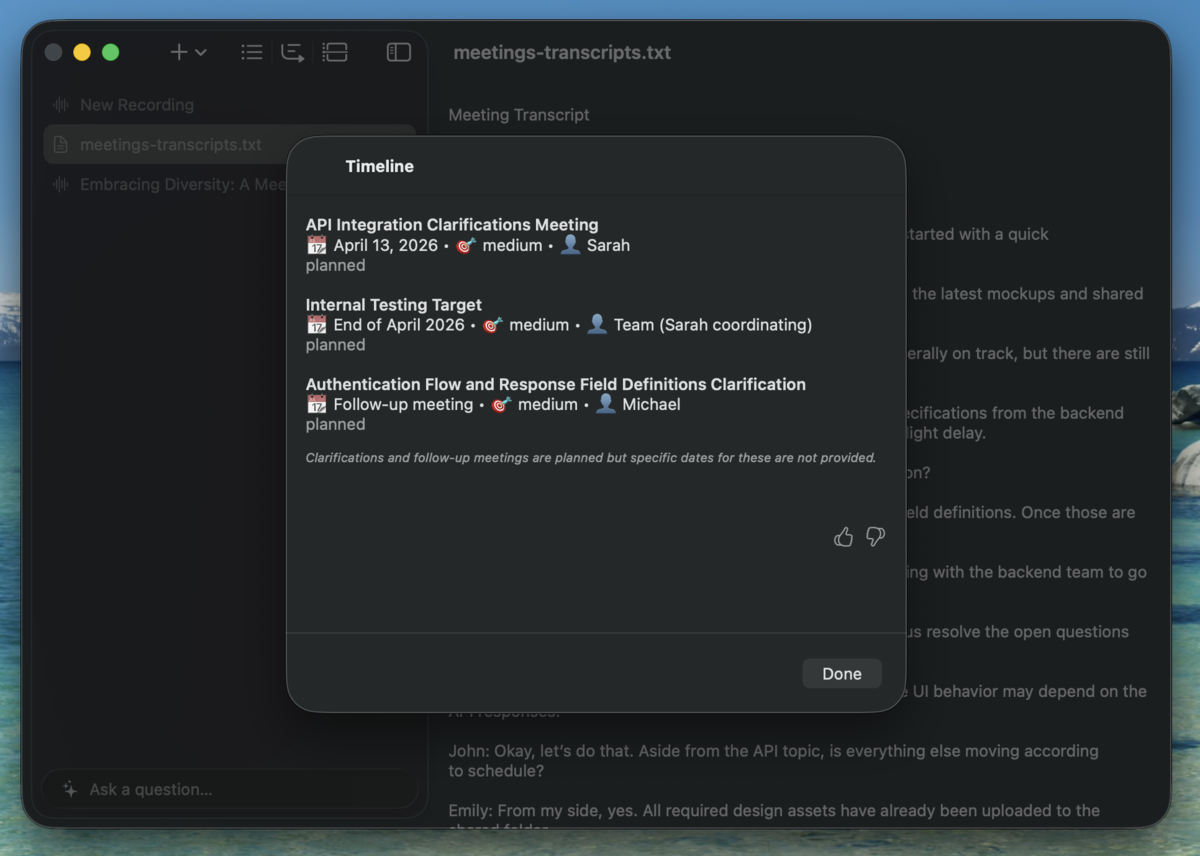
3.3 タイムラインの抽出
録音した内容やインプットしたテキストファイルなどからタイムラインを抽出、表示する機能を追加していきます。
実際にタイムラインを取得する処理は以下となります。
private func loadTimelineContent() async throws -> LanguageModelSession { let model = SystemLanguageModel(useCase: .general, guardrails: .permissiveContentTransformations) let session = LanguageModelSession(model: model, instructions: { """ You are a project timeline extraction assistant. Your task is to analyze meeting transcripts and generate a structured project timeline containing milestones and tasks. INSTRUCTIONS: ... BASE YOUR RESPONSE SOLELY ON THE PROVIDED TRANSCRIPTS. Do not add assumptions or information not present in the text. If the text does not contain tasks or deliverables, say "There are no tasks nor timelines". Here is an example, but don't copy it: """ Self.sampleTimeline }) let text = meetingItems .map { String($0.text.characters) } .joined(separator: "\n\n") let stream = session.streamResponse(to: text, generating: Timeline.self) for try await partialResponse in stream { guard let timeline = partialResponse.content.timeline else { reasoningOutput = "" continue } reasoningOutput = timeline.compactMap { guard let date = $0.date, let title = $0.title else { return nil } return Self.timelineEntryDescription( for: title, on: date, priority: "\($0.priority ?? .unspecified)", owner: $0.owner, status: $0.status ) }.joined(separator: "\n\n") + AttributedString( "\n\n" + (partialResponse.content.extractionNotes ?? "n/a"), attributes: AttributeContainer().foregroundColor(.secondary).font(.caption.italic()) ) generationState = .generating } generationState = .completed return session }
今回新たに、 SystemLanguageModel.UseCase と SystemLanguageModel.Guardrails という概念が出てきました。
まず SystemLanguageModel.UseCase は、モデルに「どういう用途で使うか」を指定します。
今回指定されている .general は、汎用的な生成・要約・抽出向けのユースケースとなっています。
.general 以外にも、.contentTagging というユースケースを指定することができます。
.contentTagging は、プロンプトに希望するタグの種類やタグ数を指定することで、モデル側が生成した回答をもとに、タグを生成してくれるようです。
詳しくは、以下の公式ドキュメントをご参照ください。
次に SystemLanguageModel.Guardrails は、「入力と出力に対する安全制御の設定」を指定することができます。
入力プロンプトとモデル出力の両方をチェックし、安全基準に違反した場合はブロックやエラーにつながるようです。
.permissiveContentTransformations は default と比較したときに、やや寛容に「テキスト変換系タスク」を許可するガードレールとなっています。
上記から、下記で定義している SystemLanguageModel は、「汎用タスク向けモデルを、変換系用途に比較的寛容な安全設定で使う」ように生成しているということになります。
SystemLanguageModel(useCase: .general, guardrails: .permissiveContentTransformations)
続いて、LanguageModelSession のインスタンス化部分をみていきます。
これまでと同様に、model には先ほど説明した SystemLanguageModel が渡されており、instructionsにはより詳細にプロンプトが追加されています。
記載されているinstructionsのポイントは以下です。
- モデルのハルシネーションを抑えるために、「BASE YOUR RESPONSE SOLELY ON THE PROVIDED TRANSCRIPTS. Do not add assumptions or information not present in the text.」と記載していること。
- Few-shot prompting として、
Self.sampleTimelineを与えることで、回答の精度を上げていること。 - ただし、出力される回答内に与えた例をコピーしないように指示していること。(Appleの方によると、結構コピーすることがあるみたい...)
上記のポイントは私自身も意識したことがなかったので、非常に参考になりました。
LanguageModelSession の生成処理以降は、
streamResponse(to: text, generating: Timeline.self)
を用いてストリーミング的に回答を受け取るようにし、アウトプットを組み立てていくようにしています。
4. 最後に
今回のWorkshopを通して、Foundation Models は単に「Appleデバイス上でLLMを使える」フレームワークではなく、アプリの体験設計そのものを広げてくれる存在だと感じました。
要約やタイトル生成、タイムライン抽出のような機能を、プライバシーや通信環境、コストを強く意識せずに組み込める点は、これまでのクラウド中心のLLM活用とは異なる大きな魅力です。
一方で、期待する出力を得るには instructions の書き方や Generable な型設計、さらに周辺フレームワークとの組み合わせ方まで含めて考える必要があり、実装者側の設計力も問われることを学びました。
今後は今回得た知見をもとに、実際のプロダクトへどう応用できるのかを検証しながら、on-device LLM 時代ならではの体験づくりを深めていきます。