はじめに
初めまして、ご縁があり2023年3月の1ヶ月間ヤプリのSREチームでインターンをさせていただいていた眞田です。 私はこのインターンの間で、ヤプリの開発で使われているSentryというツールのインフラ改善を行いました。 本記事では、インフラ改善の詳細やインターンで感じたことなどをまとめています。
内容
目的
ヤプリではフロントエンド開発のエラー監視にSentryを使用しています。しかしこのSentryは過去に構築されて以来、現在のSREメンバーが継続的にメンテナンスを主導できていない状態になっています。 そのため今回のインターンでは既存のSentryのバージョンアップを行い、メンテナンスできる状態にするといったことを目的としました。
これまでの環境
ヤプリでは、これまで単一のEC2インスタンス上にSentryをコンテナとして運用していました。Sentryで使用されるデータベースもコンテナ上で運用しており、データの損失リスクがありました。また、フロントエンドチームがSentryを頻繁に使用しているため、Sentryに問題が発生した場合、業務に大きく影響を与える可能性があります。そのため、保守や運用の容易性に配慮した設計が求められていました。
設計
最初は、SentryをECS Fargate上に構築することを考えており、以下の図のような構成を目指していました。
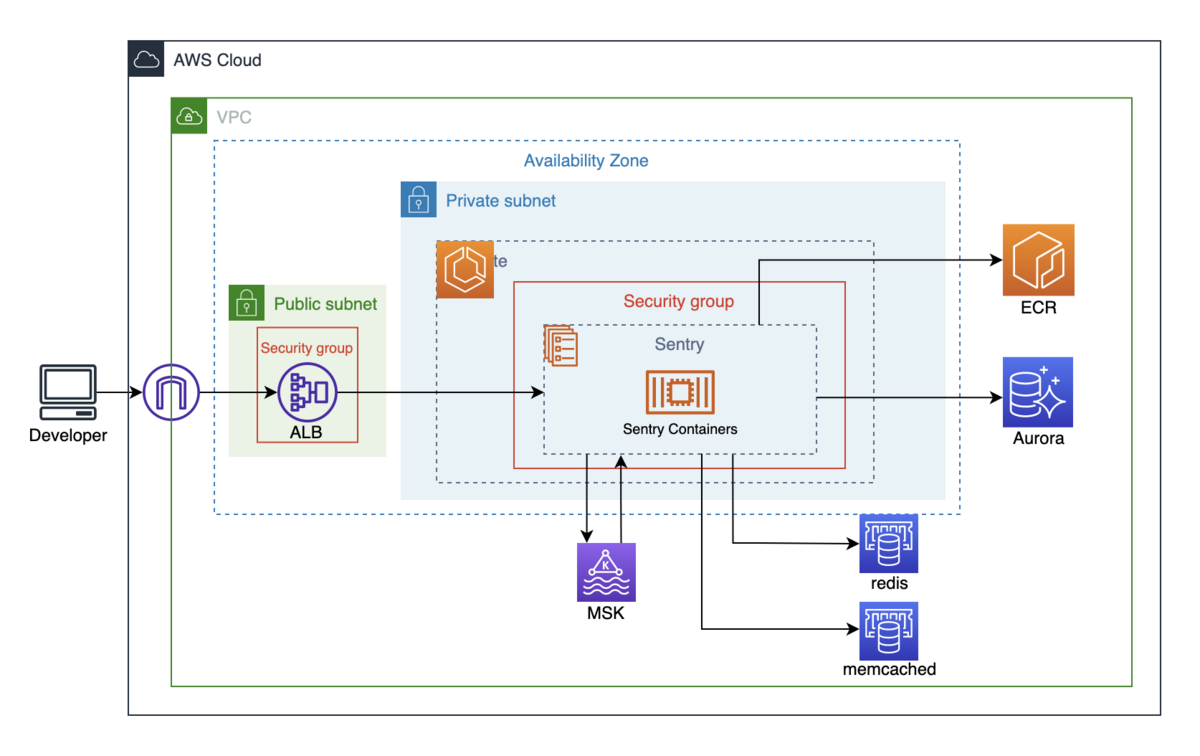
図ではECSの中にあるコンテナの数は1つしか書いていませんが、実際には複数のコンテナで構成されています。使用されているコンテナのうちいくつかはAWSのマネージドサービスを利用して代替しました。以下が代替したものになります。
PostgreSQL => Aurora(PostgreSQL)
- Sentryでは、環境変数を設定することでデータの保持期間を指定できます。期間が過ぎると、自動的に削除されます。ユースケースにもよりますが、AWSのマネージドサービスでPostgreSQLを運用することで、エラーデータを永続的に保持することができます。また、可用性が向上や、CloudWatchなどの監視ツールと組み合わせることで、将来的に運用に必要なスペックや容量の見積もることができます。
kafka, zookeeper => MSK(serverless)
Sentryにおいて、エラー発生時のデータパイプラインを構築するために使用されます。PostgreSQLと同様に、環境変数を設定することでデータの保持期間を指定できます。ログやエラーの量によっては、容量がスケールするため、ユースケースに合わせたスケーリングが必要です。しかし、今回の場合はトラフィック量が少ないことと、データを永続的に保持することを考慮して、サーバーレスを選択しました。
redis, memcached => ElastiCache(redis, memcached)
- AWSのマネージドサービスを利用することで、障害発生時に可用性を維持したり、リソースを最適化したりすることができます。想定されるトラフィック量が少ないことから、スケーラビリティに関する懸念はあまりなく、インスタンスのスペックも必要最小限で問題ないと考えられます。
しかし、いくつかの理由から、ECSを使用してSentry環境を構築することは断念しました。まず、Sentryの構成が非常に複雑であったことです。実際には、Sentryを構成するためのコンテナの数は32個あります。もちろん全てのコンテナが必要であるという訳ではありませんが、不必要なコンテナを把握したり、ECSやAWSのマネージドサービスを使用してSentryを構築するには、これらの32個のコンテナがどのように相互作用するかを理解する必要があります。
そしてもう1つの理由は、Sentry自体がDocker Composeを前提として構成されている点です。実際には、Docker Composeでコンテナ群を起動する前に、初期化用のスクリプトを実行する必要がありますが、これはDocker Compose前提の書き方がされています。つまり、コンテナ同士の相互作用から初期化用のスクリプトまで、すべてをAWSのECS用に再構築する必要があるということです。短期間の中でこれらを考慮して構築することは、現在の自分には厳しかったので、別の手段を用いて構築しました。ただし、実際に構築された事例があるため、理論的には可能だと考えられます。
実際にはEC2の中でDockerコンテナを立ち上げて、その中からいくつか切り分けられる部分を切り出すといった形を取りました。実際に切り出したのはPostgreSQLだけで、redisやmemcachedの切り出しにも取り組みましたが終わりませんでした。こちらはドキュメントを残しておいたのであとはSREチームにお任せしようと思います。
詰まったポイント
DockerとECSタスクの互換性
これは最初ECSを使用して構築しようとしたときです。まずはコンテナ32個をデプロイしてSentry起動してみようってなり、docker-compose.ymlで書かれている内容からECSのタスク定義を作成して環境を構築しようとしていました。このDockerfile⇄ECSタスク定義の互換性を最初知らなくて理解するのに時間がかかりました。頑張ってコンソールぽちぽちしてタスク定義を作っては作り直してを繰り返してました。最終的にはECSは使用しませんでしたが、結構試行錯誤したのでかなりECSに関する理解が深まったのではないかと思っています。次回はちゃんと完成を目標にしたいですね。
Sentryアーキテクチャの理解
正直こちらが一番苦労しました。sentryの構成要素がそれぞれ何のために使用されているのかについて理解するのが大変でした。SentryではSentry専用に作られているコンポーネントが多くありました。加えて自分自身kafka, redis, memcachedについても未知だったこともあり、そのあたりの理解も必要になっていました。気づいたらドキュメントやソースコードを行き来する旅をめちゃくちゃしていたような気がします。
学んだこと
今回の案件を通して、コンテナに対する理解がかなり深まったのではないかと思います。普段何となくで使っていた部分でも理解が曖昧だったのが、より詳しく知ることができました。また、プライベートでは触りにくいAWSにも色々と触ることができました。
さらに、アーキテクチャの設計やその設計に至る理由、その設計のメリット・デメリットを考えながら取り組み、設計したものに対してフィードバックしていただけるという貴重な体験もできました。学んだことはすぐに実践に移したいタイプなので、インターン終了後も、普段の技術的な活動に今回学べたことを生かしていきたいと思います。
おわりに
今回の1ヶ月間のインターンを経て、技術的なことに加えてSREに対する理解もかなり深まったと思います。インターンに参加する前は、サーバーサイドエンジニアかSREか悩んでいました。自分はSREに興味があるけれど、新卒でSREはハードルが高いと感じていました。しかし、今回のインターンを通して、SREという職種に対する思い込みが払拭されたと思います。 VSCodeとかで便利な拡張機能とかを発見した時のワクワクとか楽しさとかを感じますよね?自分はSREという職種で働くことを通してそういった技術者に向けての価値提供をしたいと思っているので、その目標に向かって頑張っていこうと思います。
参考にした書籍
今回のインターンでお世話になった書籍を載せておきます。
内容は簡単ですが、Dockerでもあまり理解していなかった部分の勉強になりました。

ECSで実際に構築する際にお世話になりました。ハンズオン形式で書かれていたのでとても参考になりました。
![AWSコンテナ設計・構築[本格]入門](https://m.media-amazon.com/images/I/518jpjD7X8L._SL500_.jpg "AWSコンテナ設計・構築[本格]入門")
インターンにおいて使用したというわけではないですが、インターン期間中にあった勉強会でメンターの方が紹介していたのに感化されて購入しました。
まだあまり読み込めていないので、インターン終わったらじっくり読もうと思います。
