
こんにちは!データサイエンス室(以下、DS室)の山本です(@__Y4M4MOTO__)です。
内定者インターン時代に全社横断のSlackデータ基盤を構築しました。作成したデータ基盤はSlack APIを叩いてその結果をBigQueryへ格納するものだったのですが、Pythonで実装したところとても工数がかかり、運用開始まで半年(正確には5ヶ月)かかりました…。その後、「Pythonで実装した処理、TROCCOならサクッと作れるのでは?」という説がふと浮かびました。
そこでこの記事では、内定者インターン時代に作成したデータ基盤を紹介するとともに、TROCCOで同様の基盤を爆速で作れるのかを検証します(半分くらい私の備忘録を兼ねています…)。
- 作成したSlackデータ基盤について
- TROCCOで実現できるかの検証
- 結び
作成したSlackデータ基盤について
なぜ作ったのか?
会社のSlackを盛り上げるためです。
当時はコロナ禍だったため働き方がオフィス出社からリモートワークへ大きく変化しており、それによって社内コミュニケーションもほぼほぼSlackでのみ行われるようになっていました。これにより、「最近雑談とか全然しなくなった気がする」「この情報、以前Slackのどこかで見た気がするけど埋もれちゃって分からない」「質問・問い合わせってどこですれば良いんだろう」等、社内コミュニケーションの活性化に課題感のある状況でした。
そこで、Slack上でのやり取りを収集することで、現在の社内コミュニケーションの活性度を可視化し、その改善施策を打ちやすくしようと考えました。
本題ではないので省略していますが、実際にはデータ基盤を作る前に、総務や最近入社した人へ社内Slackの課題感をヒアリングしたり、スポットでSlackのデータを集めて本当に社内コミュニケーションの活性度を可視化できるのかのPoCを行ったりし、データ基盤の必要性を確認していました。
全体像
作成したデータ基盤の全体像はご覧のとおりです。Slack APIのレスポンスをGCSへ保存し、その後BigQueryへロードするという処理を行っています。スクリプトはPythonで実装し、GitHub Actionsで定期実行するようにしました。
収集データ
次のデータを収集することにしました。
- 作成されているチャンネルの一覧
- ワークスペースに参加しているユーザの一覧
- 各チャンネルに投稿されているメッセージ(スレッドも含む)の一覧
データパイプライン
データパイプラインは下図のようになっています。このパイプラインを日次で実行していました。
※ 下図には書いていませんが、ユーザ一覧も取得しています。チャンネル一覧、メッセージ一覧とはパイプラインが独立しており、かつ処理もシンプルなためここでは省略しました。
- conversations.list ... ワークスペース内のチャンネル一覧を取得するAPI
- conversations.history ... 指定したチャンネルのメッセージを取得するAPI
- conversations.replies ... 指定したチャンネル、メッセージに発生しているスレッドを取得するAPI
🖼️ データパイプラインの図(クリックで展開)
ポイントは主に下記の点です。
💡 メッセージ取得対象のチャンネルを設定している
社内コミュニケーションの活性化を目的としていたため、メッセージを取得するチャンネルは部活動チャンネルや雑談チャンネルなどに絞りました。このチャンネルフィルタ処理を行うため、チャンネル一覧テーブル(channelsテーブル)を作成した後にメッセージ一覧テーブル(messagesテーブル)を作成する必要がありました。
💡 conversations.historyのレスポンスとconversations.repliesのレスポンスの結合処理をGitHub Actions上で行なっている
Slack APIではチャンネルに投稿されているメッセージとそのスレッドは別々のAPIで取得する必要があります。そのため、「メッセージ一覧」として扱うためにはこれらのレスポンスを結合する必要があります。この結合処理をPythonで実装し、GitHub Actions上で実行することで行なっていました。
このパイプラインは日次で実行していたのですが、その場合2日以上前のスレッドに返信があった場合には取得漏れが発生します。ただ、大半のスレッドは当日中に完結すると考え、この問題は無視することにしました。
かかった工数
週2のインターン&開発人数は一人、という状況で5ヶ月かかりました。インターンタスクとしてはデータ基盤を作ってからの社内コミュニケーションの活性度可視化、改善施策の実施(ソリューション開発)がメインの予定だったのですが、基盤を作るだけで終わってしまいました…。
TROCCOで実現できるかの検証
ここからは前述のSlackデータ基盤をTROCCOで実現できるか検証していきます。
作成するデータ基盤の全体像
作成するデータ基盤のパイプラインは次のとおりです。
処理はざっくり2段階に分かれます。
- TROCCOでSlack APIを叩き、その結果をBigQueryへ格納する
- BigQueryへ格納されたデータをモデリングし、チャンネル一覧テーブルとメッセージ一覧テーブルを作成する
より詳細な流れを以下に示します。
🖼️ データパイプラインの図(クリックで展開)
STEP 1|conversations_listテーブルの洗替
TROCCOのデータ転送機能で転送元を「HTTP・HTTPS転送」、転送先を「Google BigQuery」に設定します。conversations.list APIを叩いて得られたレスポンスでBigQueryの conversations_list テーブルを洗い替えます。
conversations_list テーブルを洗い替えた後は、この後の conversations_history テーブルの洗替で使いやすいよう、 channel だけカラムとして取り出したテーブル channels を作成します。イメージとしては次のようにスキーマを変更します。
conversations_listテーブルのスキーマ
{ "channel": json }
↓
channelsテーブルのスキーマ
{ "channel_id": string, "channel": json }
STEP 2|conversations_historyテーブルの洗替
同様にしてconversation.history APIを叩いて得られたレスポンスでBigQueryの conversations_history テーブルを洗い替えます。
conversations.history APIで取ってくるデータは前日分とし、そのデータで conversations_history テーブルを洗い替えます。追記ではなく洗替にした理由はリトライやワークフローのメンテナンスがしやすいためです。
conversations.history APIは引数にchannel(チャンネルID)を与える必要があるため、TROCCOのカスタム変数ループを使って前の手順で更新した conversations_list テーブルを参照しています。
conversations_history テーブルを洗い替えた後は、channel 、 ts 、 thread_ts の3つだけカラムとして取り出したテーブル conversations_history_extracted を作成します。理由は、この後のconversations_repliesテーブルの洗替、messages テーブルへの結合処理をやりやすくするためです。
STEP 3|conversations_repliesテーブルの洗替
同様にしてconversation.replies APIを叩いて得られたレスポンスでBigQueryの conversations_replies テーブルを洗い替えます。
conversations.replies APIは引数に ts(スレッドを取得したいメッセージのタイムスタンプ)を与える必要があります。そのため、TROCCOのカスタム変数ループを使って前の手順で更新した conversations_history テーブルを参照しています。したがって、 conversations_replies テーブルは前日分のデータで洗い替えられることになります。
conversations_replies テーブルを洗い替えた後は、channel 、 ts 、 thread_ts の3つだけカラムとして取り出したテーブル conversations_replies_extracted を作成します。理由は、この後の messages テーブルへの結合処理をやりやすくするためです。
STEP 4|messagesテーブルの追記
conversations_history_extracted テーブルと conversations_replies_extracted テーブルを UNION ALL で結合し、 messages テーブルに追記します。
TROCCOでの実装
上記のデータ基盤をTROCCO上で実装していきます。
次の記事が参考になったのでこちらをご覧ください。ここでは説明を省略します。 qiita.com
STEP 1|conversations_listテーブルの洗替
ワークフローは次のようになります。
conversations.list[conversations.list API実行用データ転送
設定は下図の通りです。
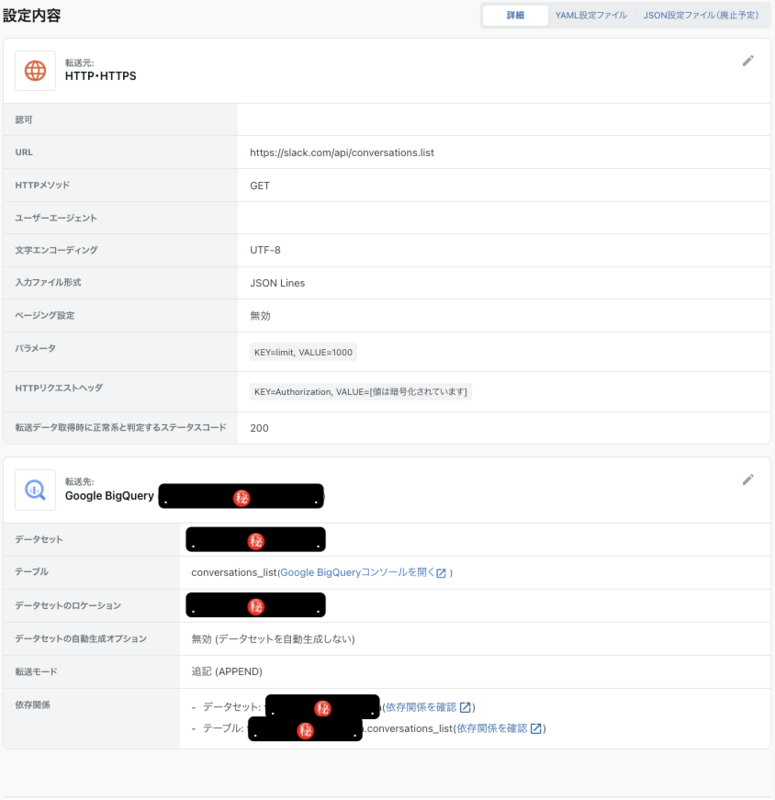
ポイントは次のとおりです。
💡入力ファイル形式をJSON Linesにする
conversations.list APIの一般的なレスポンスは次のようになっています1。
{ "ok": true, "channels": [ { "id": "C012AB3CD", "name": "general", ... }, { "id": "C061EG9T2", "name": "random", ... } ], "response_metadata": { "next_cursor": "dGVhbTpDMDYxRkE1UEI=" } }
したがって、入力ファイル形式をJSON Pathにして $.channels と指定するのが良さそうに見えます。しかし、conversations.list APIはチャンネルによってJSONオブジェクトの構造が微妙に異なることがあり、前述のJSON Pathによる指定ではTROCCOによるスキーマ検知がうまくいかないことがあります。
この問題に対処するため、レスポンスから必要部分を抽出するのではなくレスポンス全体をそのまま格納することにしました。これを実現するため、入力ファイル形式をJSON Pathにして $. と指定したのですが、空のレコードが出てくるだけでうまくいきませんでした。試行錯誤の結果、入力ファイル形式にJSON Linesを指定することでうまくいくことがわかりました。
なお、画像中ではパラメータで limit を1000に設定していますが、自動データ設定を利用する場合は一旦2など少ない値にし、自動データ設定が完了した後に1000など本来の値へ戻すようにしてください。理由は、JSON Linesとして扱った関係で channels カラムに格納される文字列が非常に長くなり、ページが固まってしまう恐れがあるためです。
Slack APIではページングをカーソルベースで行っており、next_cursorにカーソルの値が格納されています。最後のページの場合、next_cursorには空文字が入ります。
TROCCOはカーソルベースのページングに対応しているのですが、最後のページとみなす条件が「カーソルが含まれていない」「カーソルの値がnull」のみのためSlack APIには使えません(使った場合、無限ループしてしまいます)。
この点については改善要望を出してみようと思います!(TROCCOの改善要望への対応スピードはとても速く、いつも助かっています…!🙏)
なお、今回は力技でなんとか対応させてみました。詳細はこちらの記事をご覧ください。 qiita.com
channelsテーブル洗替用データマート定義
次のクエリを実行して channels テーブルを作成します。
CREATE OR REPLACE TABLE `YOUR_PROJECT_ID.YOUR_DATASET.channels` AS WITH unnest_channels AS ( SELECT channel FROM `YOUR_PROJECT_ID.YOUR_DATASET.conversations_list`, UNNEST(JSON_EXTRACT_ARRAY(channels, "$.")) AS channel ), final AS ( SELECT JSON_EXTRACT_SCALAR(channel, "$.id") AS channel_id, JSON_EXTRACT_SCALAR(channel, "$.name") AS channel_name, channel FROM unnest_channels ) SELECT * FROM final
STEP 2|conversations_historyテーブルの洗替
ワークフローは次のようになります。
conversations_historyテーブルの初期化用データマートシンクジョブ
次のクエリを実行し、 conversations_history テーブルを初期化します。
DROP TABLE IF EXISTS `YOUR_PROJECT_ID.YOUR_DATASET.conversations_history`
conversations.history API実行用データ転送ジョブ
設定は下図の通りです。
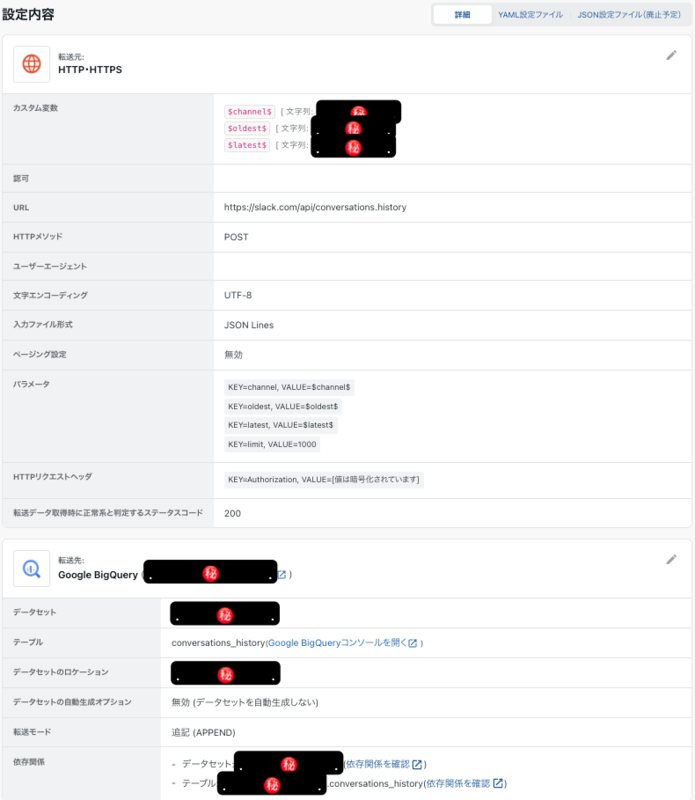
ポイントは次のとおりです。
💡カスタム変数に $channel$ 、 $oldest$ 、 $latest$ を設定する
カスタム変数ループで指定できるようにするためです。カスタム変数ループには次のようなクエリを設定します。
SELECT channel_id, UNIX_SECONDS(TIMESTAMP(CONCAT(DATE_SUB(CURRENT_DATE("Asia/Tokyo"), INTERVAL 1 DAY), " 00:00:00"))) AS oldest, -- 前日の0:00から UNIX_SECONDS(TIMESTAMP(CONCAT(DATE_SUB(CURRENT_DATE("Asia/Tokyo"), INTERVAL 0 DAY), " 00:00:00"))) AS latest, -- 今日の0:00まで FROM `YOUR_PROJECT_ID.YOUR_DATASET.channels` WHERE -- ここでメッセージ取得対象のチャンネルを絞る
💡入力ファイル形式をJSON Linesにする
ここはconversations.list API実行用データ転送と同様です。
💡転送モードは「追記(APPEND)」にする
カスタム変数ループをしながら conversations_history テーブルへレコードを追加していく必要があるため、転送モードは「全件洗い替え(REPLACE)」ではなく「追記(APPEND)」にします。
次のクエリを実行して conversations_history_extracted テーブルを作成します。
TROCCOのデータ転送機能では転送日時カラムを設定できます。今回はtransferred_atというカラム名で設定しています。重複したレコードがあった際は、転送日時が最新のレコードを正として採用するようにしています。
CREATE OR REPLACE TABLE `YOUR_PROJECT_ID.YOUR_DATASET.conversations_history_extracted` AS WITH unnest_messages AS ( SELECT channel_id, message, transferred_at, FROM `YOUR_PROJECT_ID.YOUR_DATASET.conversations_history`, UNNEST(JSON_EXTRACT_ARRAY(messages, "$.")) AS message ), extract_useful_items AS ( SELECT channel_id, JSON_EXTRACT_SCALAR(message, "$.ts") AS ts, IFNULL(JSON_EXTRACT_SCALAR(message, "$.thread_ts"), "0") AS thread_ts, -- JOINで使うのでNULLは0で補完 JSON_EXTRACT_SCALAR(message, "$.text") AS text, message, transferred_at, FROM unnest_messages ), final AS ( SELECT *, FROM extract_useful_items QUALIFY -- 転送日時が最新のレコードを正として採用 ROW_NUMBER() OVER(PARTITION BY channel_id, ts, thread_ts ORDER BY transferred_at DESC) = 1 ) SELECT * FROM final
STEP 3|conversations_repliesテーブルの洗替
ワークフローは次のようになります。
conversations_repliesテーブルの初期化用データマートシンクジョブ
conversations_historyテーブルと同様です。
conversations.replies API実行用データ転送ジョブ
設定は下図の通りです。
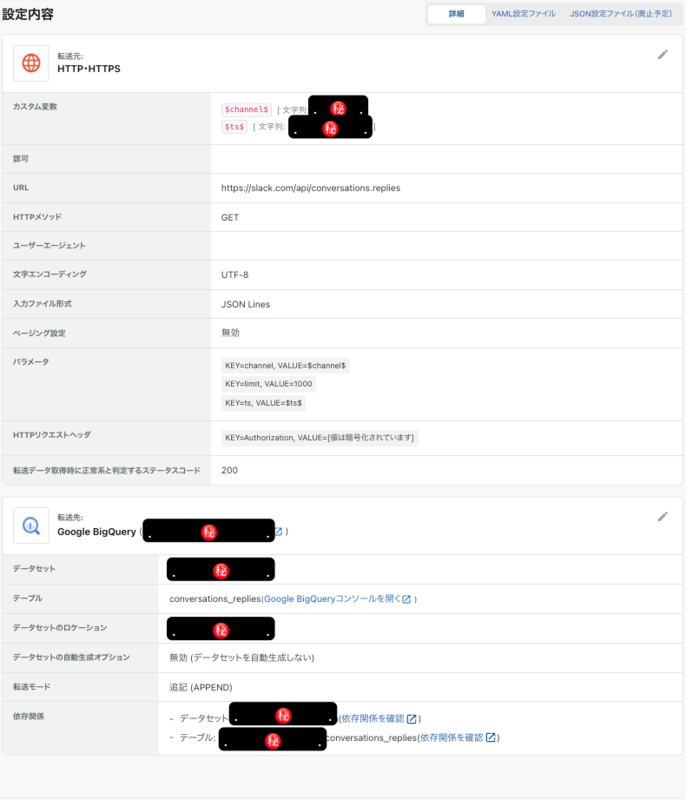
ポイントは次のとおりです。
💡カスタム変数に $channel$ 、 $ts$ を設定する
カスタム変数ループで指定できるようにするためです。カスタム変数ループには次のようなクエリを設定します。
SELECT DISTINCT -- 重複があったので除外 channel_id, thread_ts FROM `YOUR_PROJECT_ID.YOUR_DATASET.conversations_history_extracted` WHERE thread_ts != "0" -- スレッドのあるメッセージのみに絞る ORDER BY 1,2
💡転送モードは「追記(APPEND)」にする
conversations.historyテーブルと同様です。
conversations_replies_extractedテーブル作成用データマートシンクジョブ
次のクエリを実行して conversations_replies_extracted テーブルを作成します。
CREATE OR REPLACE TABLE `YOUR_PROJECT_ID.YOUR_DATASET.conversations_replies_extracted` AS WITH unnest_messages AS ( SELECT channel_id, message, transferred_at, FROM `YOUR_PROJECT_ID.YOUR_DATASET.conversations_replies`, UNNEST(JSON_EXTRACT_ARRAY(messages, "$.")) AS message ), extract_useful_items AS ( SELECT channel_id, JSON_EXTRACT_SCALAR(message, "$.ts") AS ts, JSON_EXTRACT_SCALAR(message, "$.thread_ts") AS thread_ts, JSON_EXTRACT_SCALAR(message, "$.text") AS text, message, transferred_at, FROM unnest_messages ), final AS ( SELECT *, FROM extract_useful_items QUALIFY -- 転送日時が最新のレコードを正として採用 ROW_NUMBER() OVER(PARTITION BY channel_id, ts, thread_ts ORDER BY transferred_at DESC) = 1 ) SELECT * FROM final
STEP 4|messagesテーブルの追記
次のクエリを実行して conversations_history_extracted テーブルと conversations_replies_extracted テーブルを結合し、 messages テーブルに追記します。
------------------------------------------------------------------------------------ -- 初回実行用 ------------------------------------------------------------------------------------ -- CREATE OR REPLACE TABLE `YOUR_PROJECT_ID.YOUR_DATASET.messages` -- PARTITION BY DATE(timestamp) -- CLUSTER BY channel_id -- AS ------------------------------------------------------------------------------------ -- 更新用 ------------------------------------------------------------------------------------ INSERT INTO `YOUR_PROJECT_ID.YOUR_DATASET.messages` SELECT * FROM ( SELECT *, TIMESTAMP_SECONDS(SAFE_CAST(SAFE_CAST(ts AS FLOAT64) AS INT64)) AS timestamp FROM `YOUR_PROJECT_ID.YOUR_DATASET.conversations_replies_extracted` UNION ALL SELECT *, TIMESTAMP_SECONDS(SAFE_CAST(SAFE_CAST(ts AS FLOAT64) AS INT64)) AS timestamp FROM `YOUR_PROJECT_ID.YOUR_DATASET.conversations_history_extracted` ) QUALIFY -- 転送日時が最新のレコードを正として採用 ROW_NUMBER() OVER(PARTITION BY channel_id, ts, thread_ts ORDER BY transferred_at DESC) = 1
検証結果
作成したTROCCOワークフローを動かしてみて、「内定者インターン時代に半年かけて作った全社横断のSlackデータ基盤、TROCCOなら爆速構築できる説」の検証結果は次のように結論づけました。
結論: TROCCOなら爆速で作れるが、スケールが難しい。
今回のTROCCO実装は3日で済みました。同じものを再度作るので強くてニューゲーム状態ではありましたが、とはいえ半年かかっていたものを3日で済ませられるのは素晴らしいですね…!
スケールが難しい原因は実行時間にあります。TROCCOでは性質上、Slack APIを叩くたびにEmbulkが起動します。これによりSlack APIを1回叩くのに30秒ほどかかります。私のSlackデータ基盤ではメッセージ取得対象のチャンネルが約400件あるので、400回はconversations.history APIを叩く必要があるため、ワークフローの実行に200分(約3.5時間)かかることになります。現状のPython + GitHub Actionsによる実装では10分で処理できているので、ちょっとかかりすぎ感があります…。
実行時間を短くする手としては並列処理が考えられますが、今の実装だと同じテーブルへ同時に書き込むことになるためできません。回避策としてはGCS等にJSON Linesファイルとして吐き出させる方法が考えられますが、そこまでするならTROCCOにこだわらず自前でコードを書いた方がメンテナンスしやすい気がします…。
結び
この記事では、内定者インターン時代に作成したデータ基盤を紹介するとともに、TROCCOで同様の基盤を爆速で作れるのか検証しました。実は「TROCCOなら爆速で作れるのでは?」という説は1年以上前から浮かんでおり、その時から「あぁ、TROCCOで作れば良かったのなぁ…」というモヤモヤがずっとありました。今回の検証でようやくそのモヤモヤを晴らすことができて良かったです。
ここまでお読みいただきありがとうございました🙇