はじめに
初めまして、私は今年度4月に24卒としてヤプリに入社した眞田と申します。 この記事は「New Relic Advent Calendar 2024」と「ヤプリ Advent Calendar 2024」の記事となります。 他にもたくさん興味の惹かれるような記事がございますので、ぜひご覧ください。
みなさん、NewRelicは活用されていますでしょうか? 私はこれまでNewRelic等の監視系SaaSをほとんど触ったことがなかったため、ヤプリに入社してNewRelicを触ることで少しずつ知見を深めていっています。 NewRelicではメトリクスやトレースを収集し活用することで可用性やサービスの品質を低下させないような取り組みが可能となる一方、ハードルが高く感じる方もいると思います。
そこで今回は個人的にそこまで難しくない要素を使って、ヤプリが提供しているサービスである「Yappli Data Hub」のインシデントにまつわる課題に貢献できたため、その事例について紹介します。
想定読者
- NewRelicにあまり慣れていない方
- NewRelicで組織的課題に取り組みたい方
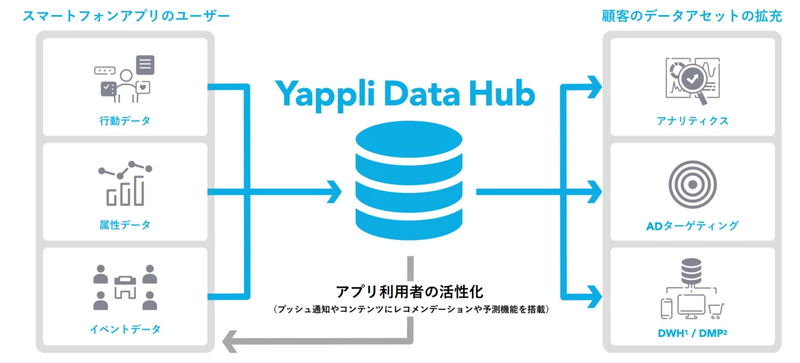
Yappli Data Hubとは
Yappli Data Hubはヤプリがアプリデータを顧客が活用できるように提供しているサービスです。 AWSとGoogle Cloudで構成されていますが、主な部分はGoogle Cloudになります。 詳しくはこちらの記事に書かれています。
Yappli Data Hubでは以下のことを行っています。
- イベントデータの収集
- 各データの統合
- 顧客への提供
Yappli Data Hubのデータ提供までの処理は深夜帯にバッチ実行で行われます。 これらの役割により、クライアントに対してアプリ活用のためのデータの提供を実現しています。
課題
素晴らしい機能を備えたYappli Data Hubですが、アプリケーションとしての機能は満たしている一方、バッチ実行の可用性が低い状態でした。 これに対して、監視体制が整っていなかったことから顧客データへの提供が失敗するなどのインシデントの際に以下のような問題が発生していました。
影響範囲(対象クライアント)がわからない
影響範囲によってビジネスサイドの方々がクライアントとのやりとりに割かれる工数も変動します。 例えば影響範囲が狭いのに対して、クライアント全体に向けたアナウンスをしたりと工数、精神的に負担が大きくなるということもありました。
またコスト面でも大きな課題がありました。 Yappli Data Hubの全クライアントに対してバッチ実行すると無視できないくらいのコストがかかり、インシデント対応の際に再実行を繰り返すととんでもない額になったこともあります。
どの部分で問題が起こっているかがわからない
インシデント対応する際に証跡から原因を探ると思いますが、そもそもまともなログが残っていないため、原因特定に時間がかかっていました。 また、どの部分で問題が発生しているのかを把握するための情報が不足していました。
そもそもインシデントに気付けない
これはもってのほかといった感じですが、アラートが不十分だったためそもそもインシデントに気付けないという問題もありました。 そういった場合にはクライアントからの問い合わせがビジネス職の方経由で報告をもらいます。
本記事ではNewRelicを活用して以上の課題に対するアプローチを比較的簡単に実施したのでそれらを紹介していきます。
Google Cloudのリソース監視
Yappli Data Hubでは「Cloud Run」「Cloud Run Functions」「Pub/Sub」「Cloud Dataflow」など様々なGoogle Cloudサービスを利用しています。
NewRelicではGoogle Cloudの各リソース監視のために、Google Cloud Platformの統合機能を利用します。これを利用することで簡単にデータを収集できます。
操作のほとんどはぽちぽちで終わります。一度サービスアカウントをGCPプロジェクトに作成できれば、各種メトリクスを取得できます。
中でもYappli Data Hubで利用されているDataflowでは要となる集計処理を行っており、ジョブの状態把握は集計処理が成功しているか失敗しているかと同義なので、アラートとしても利用可能です。またクライアントごとにバッチが分かれており、どのクライアントのジョブが失敗しているかを把握できます。
他にもBigQueryやPub/Sub, Cloud Runのメトリクスもこれを設定するだけで利用可能で、BigQueryではテーブルごとの最終更新日時を知ることができます。
ログの整備
Cloud Runを利用している部分もあり、これらのログはCloud Loggingに集約されます。Cloud Loggingに集約されたログはPub/Subを利用することでNewRelicに送ることができます。
また不要なログの整理、アラートとして利用価値のあるログの追加しました。
不要なログの整理を行なった背景として、Cloud Loggingでは適切なフォーマットのログである場合に、構造化ロギングされるのですが、適切なフォーマットでログを排出していなかったためです。 不適切なフォーマットの副作用で構造化ロギングされるべきログも非構造ログになっていたため、構造化ロギングされるために適切なフォーマットでログが排出されるように整備しました。
また影響範囲を把握するために、クライアントごとにデータが存在するかのログを付与したことで、どのクライアントに影響があるかを把握できるようにしました。
アラートの強化
ここまでで追加したものを利用して、アラートを再設計しました。 アラートの設計で重要となるのは、アプリケーションの特性を理解して適切に設計する必要があります。 これを意識することで不要なアラートによる疲弊やアラートに対する意識を向上させることができます。
Yappli Data Hubの実行はバッチ的に行われるため、失敗したかどうかを判定することが重要になります。 そのためNewRelicのStreaming MethodのEvent Timerを利用することで失敗時のシグナルを受け取ったタイミングでアラートが発火するように作成しています。
NewRelicのStreaming Methodについては弊社のテックブログで紹介していますので、こちらを参考にしてみてください。
ダッシュボードの作成
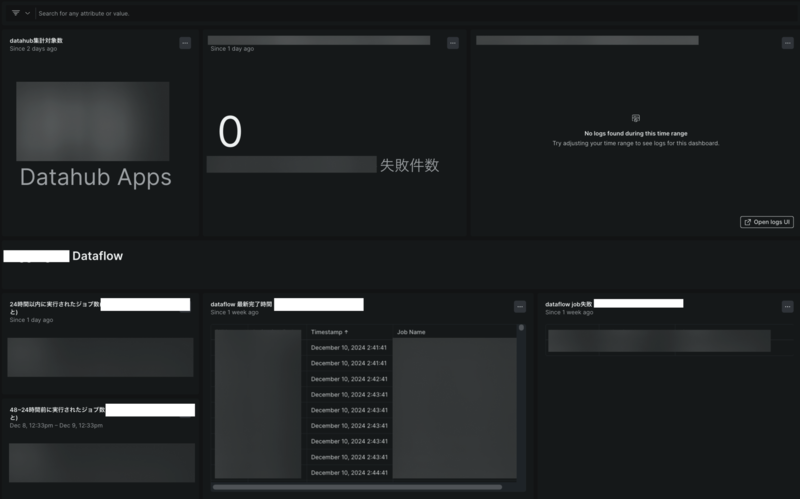
こちらもアラート同様にログやメトリクスを活用してダッシュボードを作成しました。
社内情報が含まれるのでほとんどマスクしていますが、こんな感じで失敗したクライアントを追えるようにしています。 このダッシュボードを見るだけで過去一週間分の記録が閲覧可能です。 またNewRelicではビジネス職の方々も閲覧可能なので、直接見てもらうということもできます。
おわりに
いかがだったでしょうか。 今回はNewRelicの中でも比較的簡単な取り組みで3つの改善しました。
- インシデントの検知が可能となった
- インシデントの影響範囲調査も楽になった
- どこで問題が起こっているかもわかるようになった
またこれらの設定は私自身が行なったものでありますが、チーム全体で共有活動等も行っています。 今後も引き続き、監視体制の強化に努めていきたいと思います。