はじめに
こんにちは、サーバーサイドエンジニアの加味(@kami_tsukai)です。弊社ではデータ集計バッチを Dataflow で構築しているシステムがあります。現在、Dataflow SDK の最新バージョンは2.56.0ですが、前述したシステムは非推奨バージョンの2.34.0で動いており、もちろん非推奨バージョンなので今後のサポートが急に打ち切られることもあります。またバージョン差分が大きくなりすぎるとバージョンアップが難易度が上がるので早めに取り組むことにしました。 本ブログでは、GCP Dataflow の Apache Beam SDK for Java のアップグレード対応の流れをご紹介します。
アップグレードするパイプラインの概要
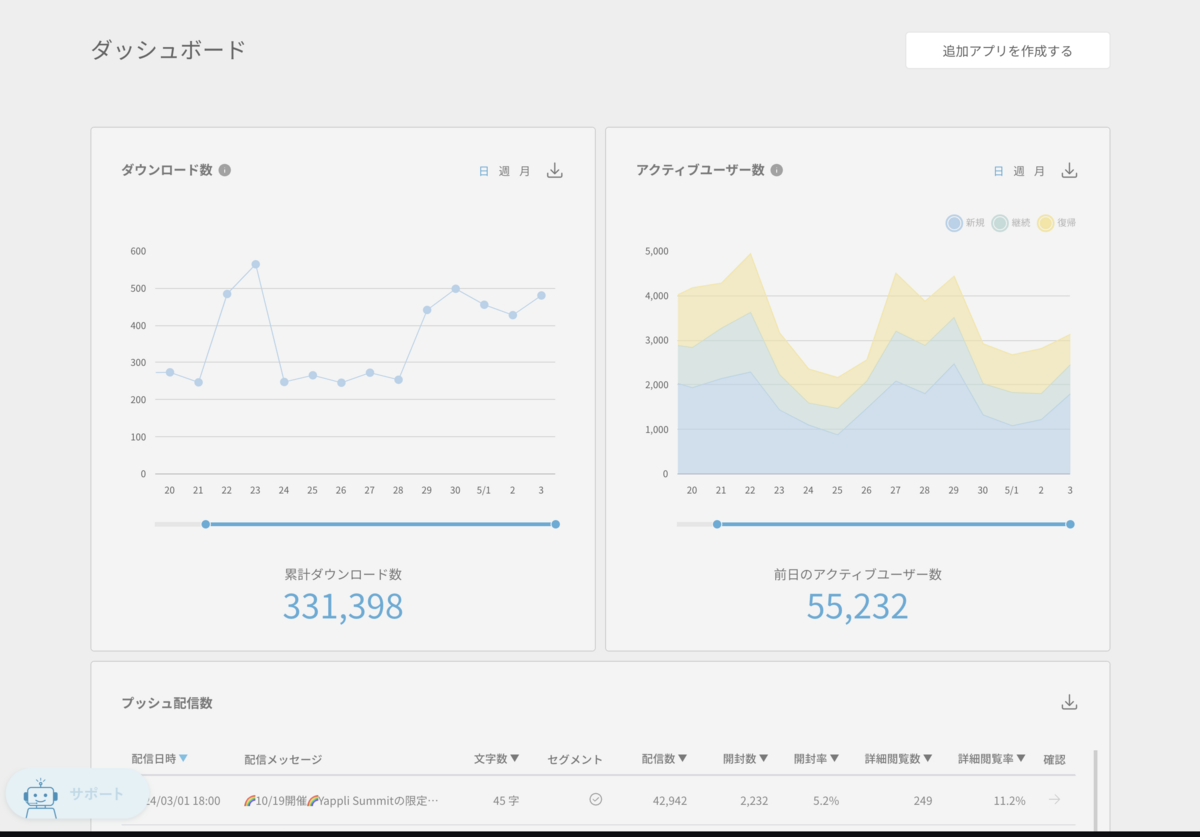
弊社では、上の画像のようにアクティブユーザー数などをCMSのダッシュボードから閲覧できるのですが、そのデータは先ほどのシステムで日次でバッチ集計したものを表示しています。パイプラインの処理の流れとしては、BigQueryで集計を行い、その結果をCSVに書き出してS3にアップロードする流れになっています。
以下のコードは実際のコードをサンプル用に書き下したものです。
// 1. パイプライン作成 Pipeline pipeline = Pipeline.create(options); PCollection<GenericRecord> rows = pipeline // 2. PCollection 作成(BigQueryから読み取る) .apply(fileName, BigQueryIO .read(SchemaAndRecord::getRecord) .withTemplateCompatibility() .fromQuery(query) .usingStandardSql() .withMethod(BigQueryIO.TypedRead.Method.DIRECT_READ) .withoutValidation() .withCoder(AvroCoder.of(avroSchema)) ) .apply(Reshuffle.viaRandomKey()) // 3. 変換処理(独自のCSV変換処理を実行) .apply(ParDo.of(new ToCSV(collect))) // 4. 外部ソースへの書き出し(S3へ書き出す) .apply(TextIO .write() .to(option.getS3Bucket() + fileName) .withSuffix(".csv") .withoutSharding() ); // 5. パイプライン実行 pipeline.run();
バージョンアップの流れ
Dataflow で利用している Apache Beam SDK for Java を 2.34.0 から 2.56.0 にアップグレードした流れを説明します。全体像は以下の通りになっています。
- Maven でのバージョン変更
- 非推奨APIの置き換え
- データパイプラインの動作確認
Maven でのバージョン変更
弊社では Maven を利用していたので、pom.xml ファイルの beam.version プロパティを新しいバージョンに更新しました。少しずつバージョンアップを行うのが一般的だとは思うのですが、1500行程度の大きさだったので一気にバージョンアップする方針で進めました。あまりにも破壊的変更が多かったり、ビルドエラーが出た場合は小刻みに上げていく方針に変えようと思いましたが、最終的には対応箇所はそこまで多くなったので一気に上げることができました。
<properties> + <beam.version>2.56.0</beam.version> - <beam.version>2.34.0</beam.version> </properties>
非推奨APIの置き換え
Apache Beam には、リリースノート や 変更ログがあったので、それらを確認しながら依存関係の更新を行いました。一通り目を通して、関係ありそうな箇所を読みました。バージョンを一気に上げると色々とビルドエラーが出たので、エラー内容を見て一つずつ潰していきました。
今回の対応では、以下の二箇所でコンパイルエラーが出ていたので対応しました。
org.apache.beam.sdk.coders.AvroCoderの非推奨対応avro.shaded.com.google.common.collect.ImmutableListの非推奨対応
1. org.apache.beam.sdk.coders.AvroCoder の非推奨対応
バージョンアップに伴い、AvroCoder クラスが廃止されていたため、リリースノート(2.46.0に記載)を参考にして新しい推奨方法に従ってコードを修正しました。具体的には、org.apache.beam.sdk.extensions.avro.coders.AvroCoder に置き換える作業を行いました。
Avro 関連のクラスは、
beam-sdks-java-coreモジュールでは非推奨となっており、いずれ削除される予定です。代わりに、org.apache.beam.sdk.extensions.avroパッケージからクラスをインポートして、新しいモジュールbeam-sdks-java-extensions-avroに移行してください。移行を簡単にするため、相対パッケージパスと、新モジュールの Avro 関連クラスの全階層は以前と同じままです。例えば、org.apache.beam.sdk.extensions.avro.coders.AvroCoderの代わりにorg.apache.beam.sdk.extensions.avro.coders.AvroCoderクラスをインポートします。
上記の説明の通りに、pom.xmlに beam-sdks-java-extensions-avro を追加して、import をorg.apache.beam.sdk.coders.AvroCoderからorg.apache.beam.sdk.extensions.avro.coders.AvroCoderに置き換えます。
<dependencies> <dependency> <groupId>org.apache.beam</groupId> <artifactId>beam-sdks-java-extensions-avro</artifactId> <version>${beam.version}</version> </dependency> </dependencies>
import org.apache.avro.Schema; import org.apache.avro.generic.GenericRecord; + import org.apache.beam.sdk.extensions.avro.coders.AvroCoder; - import org.apache.beam.sdk.coders.AvroCoder;
2. avro.shaded.com.google.common.collect.ImmutableList の非推奨対応
もう一つのエラーは、ImmutableList クラスの非推奨に関するものでした。このクラスの代替として推奨される新しいクラスを使用するようにコードを修正しました。リリースノートや公式ドキュメントを参照し、適切な代替クラスを選びました。こちらは、Apache Beam の GitHub を参照して、代替クラスを探してみました。(参考)
+ import com.google.common.collect.ImmutableList; - import avro.shaded.com.google.common.collect.ImmutableList;
データパイプラインの動作確認
これらの対応でコンパイルエラーが解消されたので、実際に動かしてみました。するとこれまで実行時間が15分程度のバッチが40分程度かかるようになり、外部ストレージの書き出し部分でタイムアウトするため、バッチが失敗するようになりました。 GCP のログエクスプローラーでログを確認すると、ワーカークラッシュループが発生して、4回目のクラッシュでバッチが失敗するようになっていました。
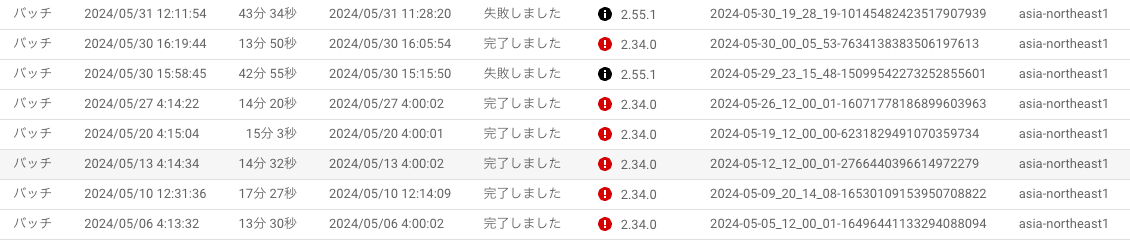
Workflow failed. Causes: S233:TextIO.Write9/WriteFiles/WriteShardedBundlesToTempFiles/GroupIntoShards/Read+TextIO.Write9/WriteFiles/WriteShardedBundlesToTempFiles/WriteShardsIntoTempFiles+TextIO.Write9/WriteFiles/GatherTempFileResults/Consolidate/Pair with random key/ParMultiDo(AssignShard)+TextIO.Write9/WriteFiles/GatherTempFileResults/Consolidate/Reshuffle/SetIdentityWindow/Window.Assign+TextIO.Write9/WriteFiles/GatherTempFileResults/Consolidate/Reshuffle/ReifyOriginalMetadata/ParDo(Anonymous)/ParMultiDo(Anonymous)+TextIO.Write9/WriteFiles/GatherTempFileResults/Consolidate/Reshuffle/GroupByKey/Reify+TextIO.Write9/WriteFiles/GatherTempFileResults/Consolidate/Reshuffle/GroupByKey/Write failed., The job failed because a work item has failed 4 times. Look in previous log entries for the cause of each one of the 4 failures. If the logs only contain generic timeout errors related to accessing external resources, such as MongoDB, verify that the worker service account has permission to access the resource's subnetwork. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors. The work item was attempted on these workers:
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
Worker ID: xxxxxxxx-yyyy-harness-j89j,
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
Worker ID: xxxxxxxx-yyyy-harness-j89j,
Root cause: SDK disconnect.
Worker ID: xxxxxxxx-yyyy-harness-j89j,
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
Worker ID: xxxxxxxx-yyyy-harness-j89j
Apache Beam の GitHub Issue を探していると、「[Bug]: Reshuffle.viaRandomKey timeout since version 2.54.0」という今回の事象に似たイシューが投稿されていました。それに伴い、2.54.0 のリリースノートを確認してみると、Runner V2がデフォルトで使用される変更が加わっていました。先ほどのイシューでは、Runner V2だとBigQueryの書き込みの部分で失敗すると記載されていたので、Runner V2を無効にして見ました。
Google Cloud Dataflow上で実行されるBeam Java Batch pipelinesは、このバージョンからデフォルトでPortable (Runner V2) になります。(他の言語は既にRunner V2になっています)。 この変更はまだDataflowサービスに展開されています。意図的に有効または無効にする方法については(Runner V2のドキュメント)を参照してください。
ということで、Runner V2を無効にする引数を渡して実行してみると実行時間が本来の15分程度まで落ち着き、バッチも成功するようになりました。はっきりと原因がわかったわけではないですが本来の期待する挙動になりました。
// 諸々省略していますが、args に --experiments=disable_runner_v2 を追加 mvn compile exec:java -Dexec.mainClass=org.xxx -Dexec.args="--experiments=disable_runner_v2"
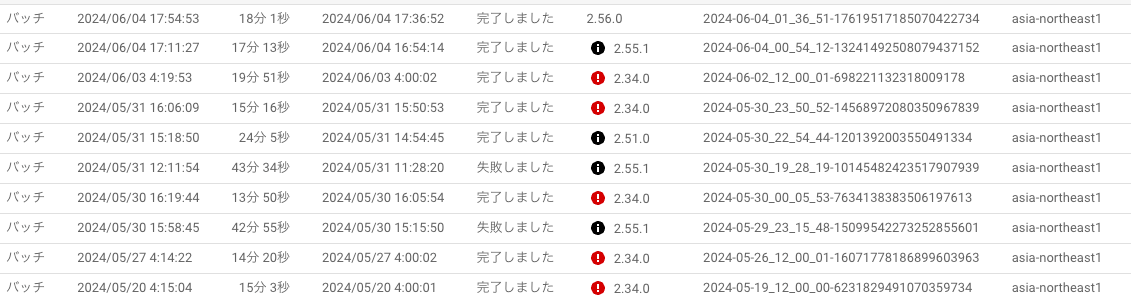
上2つの 2.56.0 と 2.55.1 が Runner V2で実行した Dataflow です。43分ほどかかっていたバッチも18分で完了しています。
まとめ
- Dataflow を感覚で触っていた部分がありましたが、PCollection、PTransform やストラグラーなどの概念を知ることができました。
- 今回初めてバージョンアップを対応したのですが、バージョンアップのイメージが沸いたのと、これまでライブラリやSDKのリリースノートなどをみることがあまりなかったので良い機会になりました。
- 定期的なアップデートが大事だと痛感しました。今回の場合、2.34.0 から 2.56.0 までの24回分のアップデート変更を追う必要があったのでかなり大変でしたが、リリースノートなどをバージョン毎に見ていれば、負担はかなり軽減できたかなと思います。
最後に
ヤプリにご興味がある方いましたら是非カジュアル面談でヤプリ社員と話しませんか?
最後まで読んでいただきありがとうございました!