こんにちは!データサイエンスグループの山本( @__Y4M4MOTO__ )です。
さて、ヤプリのデータサイエンスグループ(以下、DSグループ)では2023年から分析用データ基盤の dbt 移行に取り組んでいます。
dbt 移行に至った経緯などについては昨年開催された Yappli Tech Conference 2023 にて発表しているので、そちらをご覧いただければ幸いです。
tech.yappli.io
dbt 移行に伴い、ヤプリの各種サービスが参照しているデータマートも dbt 移行後のものへ切り替えを行っています。 dbt 移行後の分析用データ基盤(以後、 dbt 基盤)の運用が本格化してきたことで、その開発フローの方も併せて改善していきました。
この記事では、その時の話について記したいと思います。
なお、開発フロー改善は分析ツール「 Yappli Analytics 」のデータマート切り替えと並行して行いました。その時の話についてはこちらの記事をご覧ください。
tech.yappli.io
改善前の開発フロー
改善に取り組む前の時点では dbt 基盤の本番運用はまだ始まっておらず、出来上がったテーブルはどこからも参照されていない状態でした。そのため、本番環境で直接開発を行っていました。GitHub のブランチフローも開発者がそれぞれ作業用ブランチを作成し、それを main ブランチへ merge するというシンプルな方法を採っていました。
データの加工過程を図にすると次のようになります。
graph TD
%% Styling
style trocco stroke:#f95b3d,fill:#f8f8ff
style 各DSメンバーのローカルdbt環境 fill:#ff694a
style サービスDBからのデータ同期用GCプロジェクト fill:#549ffd
style サービスDBからのデータ同期用GCプロジェクト2 fill:#549ffd
style 本番用GCプロジェクト fill:#549ffd
style 本番用GCプロジェクト2 fill:#549ffd
style 本番用GCプロジェクト3 fill:#549ffd
style GitHub fill:white,stroke:#171515
%% Objects
subgraph 本番用GCプロジェクト
本番用データセット[(本番用データセット)]
UDF格納用データセット[(UDF格納用データセット)]
end
subgraph 本番用GCプロジェクト2[本番用GCプロジェクト]
UDF格納用データセット2[(UDF格納用データセット)]
end
subgraph 本番用GCプロジェクト3[本番用GCプロジェクト]
本番用データセット2[(本番用データセット)]
end
subgraph サービスDBからのデータ同期用GCプロジェクト
サービスDB用データセット[(サービスDB用データセット)]
end
subgraph サービスDBからのデータ同期用GCプロジェクト2[サービスDBからのデータ同期用GCプロジェクト]
サービスDB用データセット2[(サービスDB用データセット)]
end
subgraph trocco
本番データ更新用ワークフロー
end
subgraph 各DSメンバーのローカルdbt環境
DSメンバー1
DSメンバー2
...DSメンバー[...]
end
subgraph GitHub
DSメンバー1の作業ブランチ
DSメンバー2の作業ブランチ
mainブランチ
end
%% Flow
サービスDB用データセット -- 参照 --> 各DSメンバーのローカルdbt環境
本番用GCプロジェクト <-- 参照・書き出し --> 各DSメンバーのローカルdbt環境
DSメンバー1 -- push --> DSメンバー1の作業ブランチ
DSメンバー1の作業ブランチ -- merge --> mainブランチ
DSメンバー2の作業ブランチ -- merge --> mainブランチ
mainブランチ -- 読み取り --> 本番データ更新用ワークフロー
サービスDBからのデータ同期用GCプロジェクト2 -- 参照 --> 本番データ更新用ワークフロー
UDF格納用データセット2 -- 参照 --> 本番データ更新用ワークフロー
本番データ更新用ワークフロー -- 書き出し --> 本番用データセット2
しかし本番運用が始まったことで、本番環境で直接開発するフローから脱却する必要が生じました。
改善にあたって意識したこと
フロー整備では次の点を意識しました。
- 本番環境に影響を出さずに本番相当の開発環境を提供すること
- チームでの基盤開発を可能にすること
- GitHub におけるブランチフローや自動化といった開発作法・作り込みなどはDSグループのスキルセットで対応可能な範囲に収めること
3点目が少し特殊かなと思っています。
ヤプリのDSグループには専任のデータエンジニアはおらず、スキルセットもどちらかというとエンジニアよりアナリストに寄っているという状況でした。フロー整備にあたって他の事例を色々調べたのですが、専任のデータエンジニアを入れて作り込んでいるものが多くありました。それらをそのまま取り入れてしまうとアジリティが損なわれてしまうことになるため、そうならないよう注意しながらフローを整備する必要がありました。
改善後の開発フロー
改善した開発フローを以下に示します。なお、最初からこの形で整備できたわけではなく、
- フローを定める
- 定めたフローで実際に開発してみる(Yappli Analytics のデータマート切り替えがそれにあたります)
- 改善すべき箇所が発生したらフローを定め直す
というのを繰り返した結果がこの形です。
データの加工過程は次のようになりました。
graph TD
%% Styling
style trocco stroke:#f95b3d,fill:#f8f8ff
style trocco2 stroke:#f95b3d,fill:#f8f8ff
style 各DSメンバーのローカルdbt環境 fill:#ff694a
style サービスDBからのデータ同期用GCプロジェクト fill:#549ffd
style サービスDBからのデータ同期用GCプロジェクト2 fill:#549ffd
style 本番用GCプロジェクト fill:#549ffd
style 本番用GCプロジェクト2 fill:#549ffd
style 本番用GCプロジェクト3 fill:#549ffd
style 開発用GCプロジェクト fill:#549ffd
style -DSグループ内で共有- fill:#549ffd,stroke:white
style GitHub fill:white,stroke:#171515
%% Objects
%% -- Google Cloud
subgraph 本番用GCプロジェクト
本番用データセット[(本番用データセット)]
UDF格納用データセット[(UDF格納用データセット)]
end
subgraph 本番用GCプロジェクト2[本番用GCプロジェクト]
UDF格納用データセット2[(UDF格納用データセット)]
end
subgraph 本番用GCプロジェクト3[本番用GCプロジェクト]
本番用データセット2[(本番用データセット)]
検証用データセット2[(検証用データセット)]
end
subgraph サービスDBからのデータ同期用GCプロジェクト
サービスDB用データセット[(サービスDB用データセット)]
end
subgraph サービスDBからのデータ同期用GCプロジェクト2[サービスDBからのデータ同期用GCプロジェクト]
サービスDB用データセット2[(サービスDB用データセット)]
end
subgraph 開発用GCプロジェクト
DSメンバー1の開発用データセット[(DSメンバー1の開発用データセット)]
DSメンバー2の開発用データセット[(DSメンバー2の開発用データセット)]
...DSメンバーの開発用データセット[(...)]
subgraph -DSグループ内で共有-
開発環境でのUDF格納用データセット[(UDF格納用データセット)]
開発環境でのサービスDB用データセット[(サービスDB用データセット)]
end
end
%% -- trocco
subgraph trocco
本番データ更新用ワークフロー
検証データ更新用ワークフロー
end
subgraph trocco2[trocco]
本番テーブル複製用ワークフロー
本番UDF複製用ワークフロー
データソース複製用ワークフロー
end
%% -- dbt
subgraph 各DSメンバーのローカルdbt環境
DSメンバー1
DSメンバー2
...DSメンバー[...]
end
%% -- GitHub
subgraph GitHub
topic/チケット1
topic/チケット2
stagingブランチ
developブランチ
mainブランチ
end
%% Flow
本番用データセット -- 読み取り --> 本番テーブル複製用ワークフロー
UDF格納用データセット -- 読み取り --> 本番UDF複製用ワークフロー
サービスDB用データセット -- 読み取り --> データソース複製用ワークフロー
本番テーブル複製用ワークフロー -- 設置 --> DSメンバー1の開発用データセット
本番テーブル複製用ワークフロー -- 設置 --> DSメンバー2の開発用データセット
本番UDF複製用ワークフロー -- 設置 --> 開発環境でのUDF格納用データセット
データソース複製用ワークフロー -- 設置 --> 開発環境でのサービスDB用データセット
DSメンバー1の開発用データセット <-- 参照・書き出し --> DSメンバー1
DSメンバー2の開発用データセット <-- 参照・書き出し --> DSメンバー2
開発環境でのサービスDB用データセット <-- 参照・書き出し --> 各DSメンバーのローカルdbt環境
開発環境でのUDF格納用データセット <-- 参照・書き出し --> 各DSメンバーのローカルdbt環境
DSメンバー1 -- push --> topic/チケット1
DSメンバー2 -- push --> topic/チケット2
topic/チケット1 -- merge --> stagingブランチ --> developブランチ
topic/チケット2 -- merge --> developブランチ
developブランチ -- merge --> mainブランチ
stagingブランチ -- 読み取り --> 検証データ更新用ワークフロー
mainブランチ -- 読み取り --> 本番データ更新用ワークフロー
サービスDBからのデータ同期用GCプロジェクト2 -- 読み取り --> trocco
UDF格納用データセット2 -- 読み取り --> trocco
検証データ更新用ワークフロー -- 書き出し --> 検証用データセット2
本番データ更新用ワークフロー -- 書き出し --> 本番用データセット2
工夫点などを以下で紹介していきます。
本番用と開発用で GC プロジェクトを分離
Google Cloud プロジェクト(以下、 GC プロジェクト)は本番用と開発用で分けることにしました。開発用の方ではデータセットの削除なども気軽に行えるようにしており、柔軟性を持たせています。
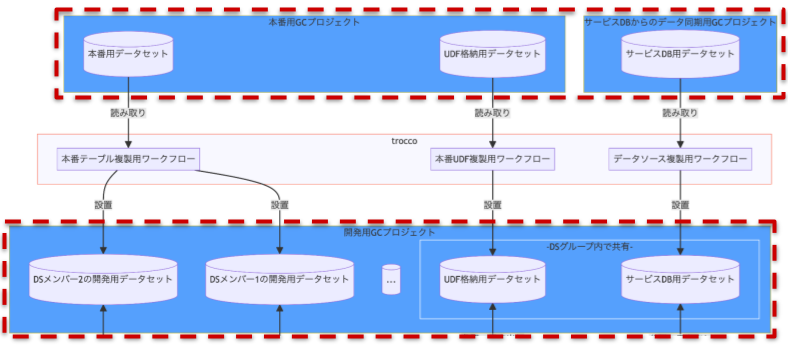 データ加工過程)本番用と開発用で GC プロジェクトが分離されている部分
データ加工過程)本番用と開発用で GC プロジェクトが分離されている部分
データセットを開発者毎に分離
データセットはDSメンバー毎に分離させることにしました。これにより、メンバー同士でデータセットが競合しなくなり、並列で dbt 基盤の開発を行えるようにしています。
なお、Git ブランチごとに分離させることも考えましたが、開発フローが成熟していないうちにそこまで作り込んでしまうのはリスクが高いと考え、採用しませんでした。
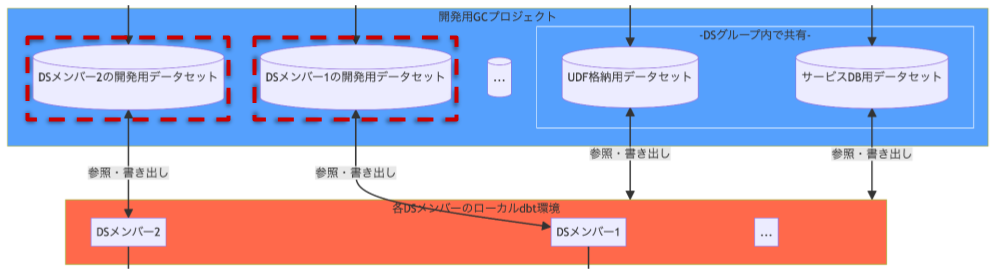 データの加工過程)データセットが開発者毎に分離されている部分
データの加工過程)データセットが開発者毎に分離されている部分
本番テーブルを開発用 GC プロジェクトへ複製
dbt 基盤の開発が行いやすいよう、本番テーブル各種を開発用 GC プロジェクトへ複製する仕組みを用意しました。
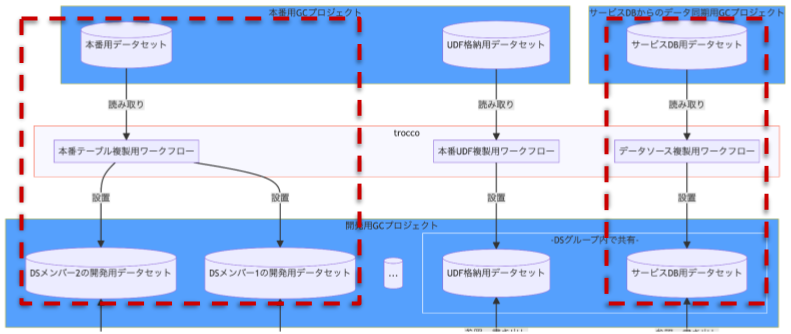 データ加工過程)本番テーブルを開発用 GC プロジェクトへ複製している部分
データ加工過程)本番テーブルを開発用 GC プロジェクトへ複製している部分
これによりデータの鮮度を固定して基盤開発が行えるため、開発効率を高めることができます。複製する仕組みは trocco のカスタム変数ループ実行と BigQuery のテーブル クローン機能を利用しました。詳細は次の記事をご覧ください。
qiita.com
テーブル クローン機能はベーステーブルからの変更分に対してストレージ費用が発生する仕様となっています1。今回のケースでは変更は発生しないので、複製にかかる費用も抑えられています。
今回は trocco のカスタム変数ループ実行 + BigQuery のテーブル クローン機能で複製する方法を採りましたが、 dbt を使っているなら
dbt clone を使った方法のほうが適切な気もしており、今後検証を行う予定です
なお、前述の「本番テーブル」は大きく分けて次の2種類があり、それぞれ複製先を変えています。
- サービスの DB 等から同期されたテーブル(以下、データソース)
- データソースから dbt で加工して作ったテーブル
前者は1箇所に複製し、全ての開発者がそこを参照して開発するようにしました。開発者によって異なる鮮度で複製したくなるケースも考えましたが、発生する見込みが今の所ないこと、そのケースを考慮したことで運用が複雑になる方がリスクになることから、考慮しないことにしました。
後者は開発者自身のデータセットへ複製するようにしました。
本番 GC プロジェクトにある UDFも開発用 GC プロジェクトへ複製
Yappli Analytics の dbt 移行に取り組む前では、 BigQuery の UDF は dbt プロジェクトでは管理せず、 UDF 用のデータセットを用意することで管理していました。この管理方法を採っていた理由は、 UDF として実装した処理をデータ基盤だけでなくアドホックな分析でも利用できるようにするためです。
初期の開発フローでは開発中も本番用の UDF を利用する想定でした。しかし、実際にやってみると次のようなケースに対応できないことが分かったため、 UDF も開発用に複製することにしました。
- 開発のために日付系 UDF の基準日を固定したい
- 既存 UDF に変更を加えたい場合の動作検証が行えない
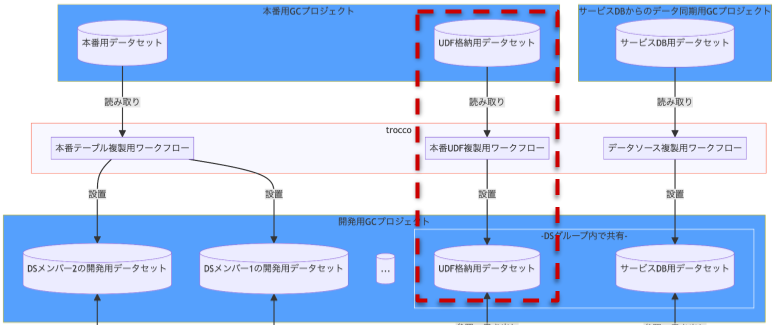 データ加工過程)本番 GC プロジェクトにある UDF を開発用 GC プロジェクトへ複製している部分
データ加工過程)本番 GC プロジェクトにある UDF を開発用 GC プロジェクトへ複製している部分
複製は trocco のカスタム変数ループと BigQuery の INFORMATION_SCHEMA.ROUTINES を使って行っています。詳細は次の記事をご覧ください。
qiita.com
後に dbt macro で CREATE FUNCTION する運用が可能なことを知り、それであればアドホックな分析でも利用可能にしつつ dbt で管理できるようになるため、現在 UDF の dbt macro 化を検討中です。
知ったきっかけは次の記事です:
medium.com
Git/GitHub のブランチフロー策定
ブランチは次の4種類で運用することにしました。
| ブランチ |
役割 |
| main |
・本番環境のコードを置いておくブランチ |
| develop |
・開発の主軸となるブランチ |
| topic |
・新規開発や既存改修などを行うためのブランチ
・チケットごとにブランチを切る |
| staging |
・既存サービスに影響のある変更をリリースする際の検証用ブランチ |
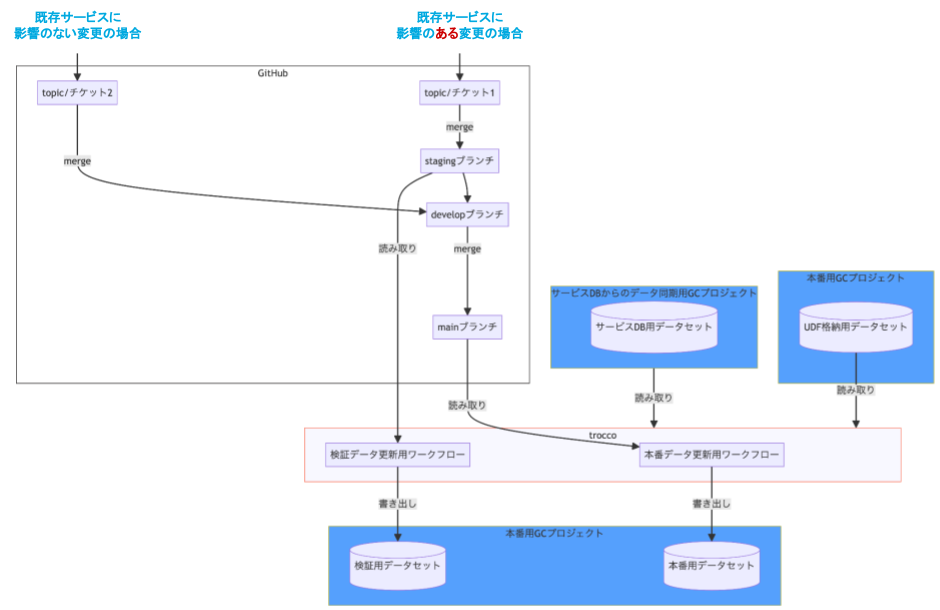 データ加工過程)Git/GitHub のブランチフロー
データ加工過程)Git/GitHub のブランチフロー
基本的には topic → develop → main の順に merge してリリースしていきますが、既存サービスに影響のある変更(例えば、今回のようなデータマートの切り替えなど)の場合は develop ブランチへの merge の前に staging ブランチを挟むようにしています。
staging ブランチの内容を検証できるよう、 trocco 上に本番環境を再現した検証環境を用意しています。この環境下では、 trocco ワークフローを実行することで staging ブランチの内容を実行し、本番のデータソースや UDF を参照し、本番用 GC プロジェクトに用意した検証用データセットへテーブルを出力するようになっています。
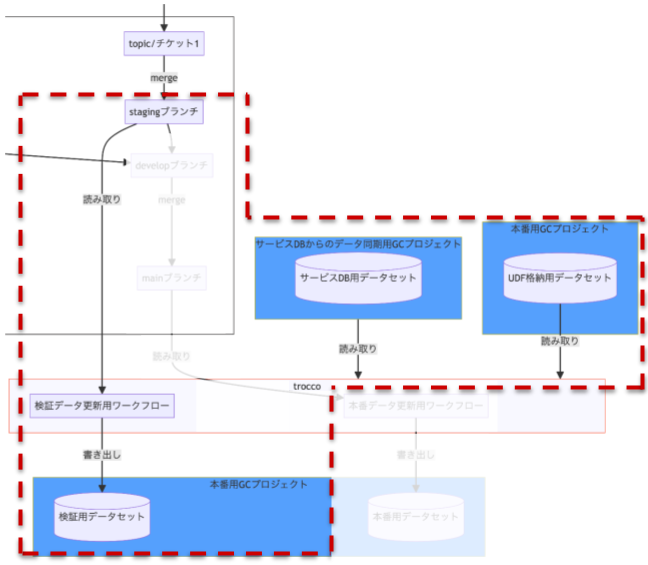 データ加工過程)検証環境部分
データ加工過程)検証環境部分
なお、検証したい内容に併せてワークフローの内容を変更する必要があります。変更が必要になるのは下図の次の箇所です。
dbt run --select (更新が必要な上流テーブル)dbt run --select (検証用テーブル)
graph TD
本番テーブル複製用ジョブ
subgraph 検証データ更新用ジョブ
dbt_create_view[dbt run --select config.materialized:view]
dbt_update_upstream_table[dbt run --select (更新が必要な上流テーブル)]
dbt_update_staging_table[dbt run --select (検証用テーブル)]
end
%%
本番テーブル複製用ジョブ --> 検証データ更新用ジョブ
dbt_create_view --> dbt_update_upstream_table --> dbt_update_staging_table
できれば変更不要にしたかったのですが、そうすると dbt run の対象テーブルが増えてスキャン料が多くなってしまったり、メンテナンスが複雑になってしまったりするため、一旦手作業で変更するようにしています。
state:modified で差分のあったモデルだけ更新するようにすると良いのかな…?と思っており、今後検証していきたいなと思っています。
次の記事が参考になっています:
zenn.dev
結び
この記事では、dbt 基盤の開発フローを改善した話について紹介しました。改善後のフローで実際に dbt 基盤の開発を行なったのは現状ほぼ私だけのため、他の DS メンバーもこのフローにしたがって開発できるようこれからレクチャー等を行なっていく予定です。
また、フローはかなり手探りで組んでいったため、まだまだ改善すべき点があります。このあと取り組む改善についてはまたどこかでお話しできればと思っています!
ここまでお読みいただきありがとうございました!この記事を読んでヤプリのデータ基盤開発に興味が出た方、ぜひカジュアル面談でお話ししましょう!
open.talentio.com