こんにちは!データサイエンスグループの山本です( @__Y4M4MOTO__ )です。今年の4月で入社して1年が経ちました。あっという間ですね…。
さて、ヤプリのデータサイエンスグループ(以下、DSグループ)では2023年から分析用データ基盤の dbt 移行に取り組んでいます。
dbt 移行に伴い、ヤプリの各種サービスが参照しているデータマートも dbt 移行後のものへ切り替えを行っています。昨年12月には、アプリプラットフォーム「 Yappli 」の CMS ダッシュボード(アクティブユーザ数やプッシュ通知の開封率などを確認できます)のデータマート切り替えが完了しました。
そして今年の4月、分析ツール「 Yappli Analytics 」のデータマート切り替えも完了しました。この記事では、その時の話について記したいと思います。
また、このときデータマート切り替えだけでなく dbt 移行後の分析用データ基盤(以後、 dbt 基盤)を開発するためのフロー整備も行いました。そちらについてはこちらの記事に記しましたので、併せてご覧いただければ幸いです。
そもそも「 Yappli Analytics 」とは?
Yappli Analytics はアプリ運用に役立つデータにアクセスできるダッシュボードです。アプリユーザのアクティブ状況やプッシュ通知の開封状況などを確認することができます。

詳細は次の記事をご確認ください。
また、 Yappli Analytics の裏側では共通のテーブルから顧客ごとにデータを出し分けるマルチテナントな機構が動いています。そちらについては、最近公開した次の記事にて解説されているので、よろしければこちらもご覧ください。
dbt へ移行する前と後の Yappli Analytics の基盤状況
dbt 移行前の Yappli Analytics のデータ更新は次のような構成で行っていました。
Yappli Analytics 自体は Looker Studio で作られたダッシュボードです。 Looker Studio で参照するデータマートは BigQuery 上に作られています。 dbt 移行前はデータマートの更新を trocco 上にワークフローを構築して行っていました。
dbt 移行後、データ更新の仕組みは次のように変わりました。集計済みテーブルの作成自体は dbt で行い、 trocco を使って Looker Studio が利用している Google Cloud プロジェクトへテーブルクローンするようにしています。テーブルクローンで別データセットへ複製している理由は、権限管理を行いやすくするためです。
dbt 移行の流れ
dbt 移行は次のような流れで行いました。
- 各テーブルの更新用クエリを dbt モデル化
- dbt モデルを既存テーブルと並行して稼働させ、データマート切り替え時に差分が出ないか検証
- Looker Studio の参照元の切り替え
STEP 1|各テーブルの更新用クエリを dbt モデル化
dbt モデル化は次の流れで行いました。
- 既存クエリを条件を固定して実行
- 実行結果を保存
- 既存クエリを dbt で刷新して実行
- 既存テーブルと dbt 版テーブルを比較し、差分が出ていないか確認

dbt モデルでつまづいた点は、既存テーブルとdbt版テーブルとの差分チェックです。具体的には下記の点でつまずきました。
データソースの鮮度を固定しなかったため、そもそも比較が大変だった
dbt モデルでつまづいた点は、既存テーブルとdbt版テーブルとの差分チェックです。具体的には下記の点でつまずきました。
dbt モデル化を始めた当初はdbtで作ったテーブルについてのみ開発環境へ複製するようにしており、データソースについては複製していませんでした。今回作るのはデータマートであるため、その前段のテーブルだけ複製していれば大元のデータソースは複製不要だと考えていたからです。
しかし、実際やってみると、データソースを参照する必要があるテーブルがいくつもありました。データソースを複製せずにこれらのテーブルについて差分チェックを行うには、前述の1~4の手順をほぼ同タイミングで実行する必要がありました。しかも、チェックのたびに実行を行う必要があり、かなり時間と労力を取られていました。
そこで、データソースについても複製の仕組みを整えることで対処しました。
dbt 移行中に解消された技術負債が、比較の際に差分になってしまっていた
dbt 移行の際に URL のデコードなどいくつかの技術負債も同時に解消されていました。しかし、それらが比較の際に差分として出てしまい、チェックしたい差分(データソースの切り替えミスや集計ロジックのミスなど)がそれらに埋もれて確認できなくなってしまっていました。
特に困ったのが、上流のテーブルにて、テーブルの更新方法が INSERT から UPSERT (厳密には dbt の materialized=”incremental” )へ改善されていたケースです。「 dbt 版テーブルには存在しているデータが既存テーブルでは欠損している」という状況が発生し、差分チェックで差分が出てしまった際の原因調査に時間を取られてしまっていました。
そこで、既存クエリに技術負債の解消を行なったものを用意し、それを比較に用いることにしました。これにより、技術負債解消に起因した差分が出ないようになり、チェックしたい差分が確認できるようになりました。
ORDER BY の結果が完全に固定されていない箇所があり、比較の際に差分になってしまっていた
ヤプリの分析用データ基盤ではアプリ利用者のイベントログ(スクリーン、イベント)も扱います。イベントログは量が膨大な上にストリーミング方式で収集しているため、ログのタイムスタンプが重複してしまうことがあります。そのため、タイムスタンプのみで ORDER BY しているとソート順が固定されず、実行タイミング等で順番が変わってしまう可能性があります。これまでは特段問題になりませんでしたが、今回のdbt化では差分チェックを行うため問題となりました。
具体例を用いて説明します。
例えば、アプリのスクリーンイベントを記録した次のようなテーブル(名前は events テーブルとします)があったとします。
| event_id | app_id | user_id | screeen_id | timestamp |
|---|---|---|---|---|
| 1 | app1 | user1 | screen1 | 2024-04-01 10:00:00 |
| 2 | app1 | user1 | screen3 | 2024-04-01 10:20:00 |
| 3 | app1 | user1 | screen2 | 2024-04-01 10:20:00 |
| 4 | app1 | user1 | screen2 | 2024-04-01 11:00:00 |
このテーブルからアプリごとに各スクリーンの滞在時間を計算する場合、次のようなクエリになります。
WITH lead_timestamp AS ( SELECT event_id, app_id, screen_id, timestamp, LEAD(timestamp) OVER (PARTITION BY app_id, user_id ORDER BY timestamp) AS timestamp_lead FROM events ) SELECT event_id, app_id, screen_id, timestamp, timestamp_lead, TIMESTAMP_DIFF(timestamp_lead, timestamp, SECOND) AS ts_diff FROM lead_timestamp ORDER BY event_id
ここで問題となるのが次の行です。
LEAD(timestamp) OVER (PARTITION BY app_id, user_id ORDER BY timestamp) AS timestamp_lead
この行では app_id, user_id ごとに timestamp でソートした上で LEAD() を行っています。しかし、これだと `event_id=2 の行と event_id=3 のソート後の位置が固定されておらず、実行タイミング等で変わってしまう可能性があります。これにより ts_diff の結果が変わってしまいます。
こちらについては、 ORDER BY するカラムに event_id を追加することで対処しました。
- LEAD(timestamp) OVER (PARTITION BY app_id, user_id ORDER BY timestamp) AS timestamp_lead + LEAD(timestamp) OVER (PARTITION BY app_id, user_id ORDER BY timestamp, event_id) AS timestamp_lead
STEP 2|dbt モデルを既存テーブルと並行して稼働させ、データマート切り替え時に差分が出ないか検証
dbt モデル化が完了したら、実際に検証環境下で稼働させてみて、データマート切り替え時に差分が出ないかを検証しました。
その際、 incremental モデルの更新方法を誤っていたことがわかり修正する、といったことがあったのでそちらについて紹介します。
既存テーブルの中には UPSERT で更新しているテーブルもありました。それらのテーブルには以下の性質があります。
- 日/週/月という異なる集計粒度のデータを持っている
- UPSERT する範囲は「当月を含む最新週以降」
- 日付単位でパーティションを設定している
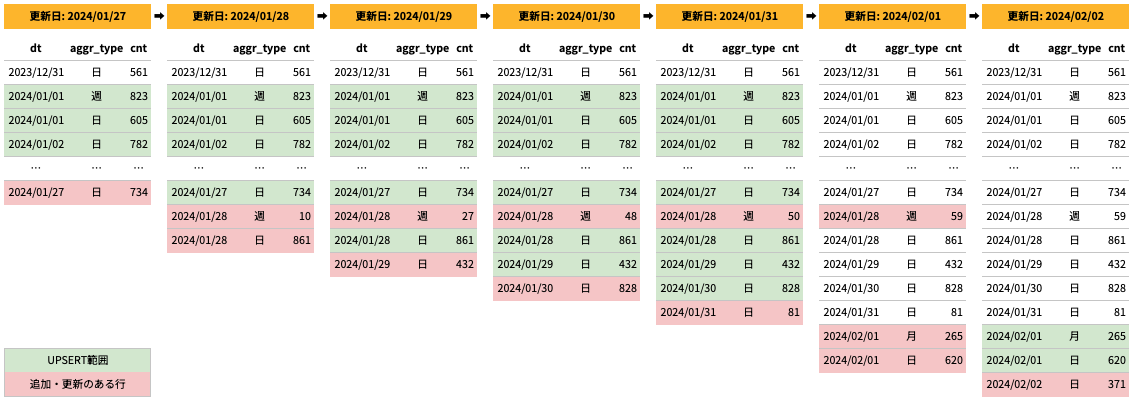
イメージとしては次のようなテーブルです。
| dt | aggr_type | cnt |
|---|---|---|
| 2024/01/27 | 日 | 734 |
| 2024/01/28 | 週 | 59 |
| 2024/01/28 | 日 | 861 |
| 2024/01/29 | 日 | 432 |
| 2024/01/30 | 日 | 828 |
| 2024/01/31 | 日 | 81 |
| 2024/02/01 | 月 | 265 |
| 2024/02/01 | 日 | 620 |
| 2024/02/02 | 日 | 371 |
UPSERT処理は次のようなクエリで行っていました。
-- 昨日基準での月初を取得するUDF CREATE TEMP FUNCTION from_date_month() AS (DATE_TRUNC(DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY), MONTH)); -- 昨日基準での月初の週の月曜日を取得するUDF CREATE TEMP FUNCTION from_date_week() AS (DATE_TRUNC(DATE_TRUNC(DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY), MONTH), ISOWEEK)); DELETE FROM 対象テーブル WHERE (dt >= from_date_month() AND aggr_type != "週") OR (dt >= from_date_week() AND aggr_type = "週") ; INSERT 対象テーブル WITH 〜〜(中略)〜〜 SELECT * FROM final WHERE -- UPSERT 範囲 (dt >= from_date_month() AND aggr_type != "週") OR (dt >= from_date_week() AND aggr_type = "週") ;
したがって、月末周辺になると UPSERT 範囲は次のように変化していきます。
| CURRENT_DATE() | 曜日 | from_date_week() | from_date_month() |
|---|---|---|---|
| 2024/01/27 | 日 | 2024/01/01 | 2024/01/01 |
| 2024/01/28 | 月 | | | | |
| 2024/01/29 | 火 | | | | |
| 2024/01/30 | 水 | | | | |
| 2024/01/31 | 木 | | | ↓ |
| 2024/02/01 | 金 | ↓ | 2024/02/01 |
| 2024/02/02 | 土 | 2024/01/29 | | |
| 2024/02/03 | 日 | | | | |
| 2024/02/04 | 月 | | | | |
| 2024/02/05 | 火 | | | | |
| 2024/02/06 | 水 | | | | |
これにより、テーブルは次のように更新されます。
これを、そのまま incremental モデルへ次のように実装しました。
SELECT * FROM final {% if is_incremental() %} -- this filter will only be applied on an incremental run WHERE (dt >= from_date_month() AND aggr_type != "週") OR (dt >= from_date_week() AND aggr_type = "週") {% endif %}
しかし、この実装だと (dt=2024/01/28, aggr_type=日) の行が欠損してしまいます。
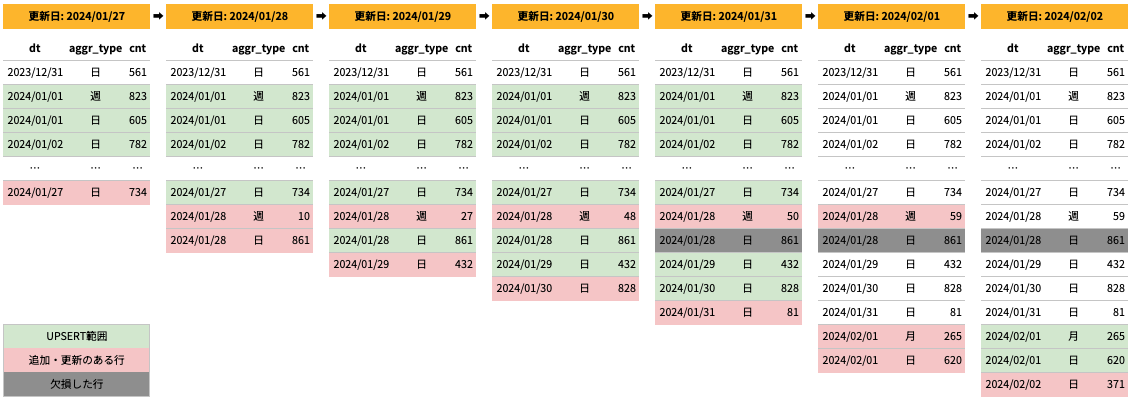
原因は incremental モデルの incremental_strategy を insert_overwrite にしていたところにあります。
insert_overwrite はパーティションをまるごと入れ替えることでデータを更新します。前述の通り、テーブルは日付単位でパーティションを設定しています。加えて、 2024/02/01 の実行では (dt=2024/01/28, aggr_type=週) の行を更新します。この更新は 2024/01/28 のパーティションテーブルを入れ替えることによって行われます。このとき、 (dt=2024/01/28, aggr_type=日) 行は更新されないため、入れ替え後のパーティションテーブルには含まれないことになります。これにより、 (dt=2024/01/28, aggr_type=日) 行が欠落します。

そこで、これまで
aggr_type=”週”の場合、昨日基準での月初の週の月曜日aggr_type!=”週”の場合、昨日基準での月初
で更新していたのを全て「昨日基準での月初の週の月曜日」で更新するよう統一しました。
SELECT * FROM final
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
WHERE
- (dt >= from_date_month() AND aggr_type != "週")
- OR (dt >= from_date_week() AND aggr_type = "週")
+ dt >= from_date_week()
{% endif %}
これにより、集計粒度が違っていても同一タイミングでデータが書き変わるため、パーティション入れ替えによってデータが欠損しなくなりました。

このときの原因調査にはこの記事がとても参考になりました。
STEP 3|Looker Studio からデータソース切り替え
Yappli Analytics が参照しているデータマートを dbt で作成したものへ実際に切り替えていきます。いきなり本番切り替えを実施するのは怖かったので、 Yappli Analytics (= Looker Studio ダッシュボード)の複製を作成し、そちらで予行演習を行なってから本番切り替えを行いました。
予行演習で切り替え作業時のちょっとしたつまづきポイントを洗い出したり、切り替え手順書を作成できたおかげで、本番切り替えをスムーズに行うことができました。
結び
この記事では、 Yappli Analytics のデータマートを dbt で作ったものへ切り替えた話について紹介しました。これを機に、これから Yappli Analytics をどんどん進化させていければと思っています!
ここまでお読みいただきありがとうございました!プラットフォーマーという立場で、データソリューションをつくってみたい方、ぜひカジュアル面談にてお話ししましょう!