はじめに
こんにちは、サーバーサイドエンジニアの加味(@kami_tsukai)です。
弊社には、iOS もしくはAndroid 端末からそれぞれの任意のアプリの起動、または任意のウェブページ(アプリダウンロードページなど)へ転送するためのQRコード(URL)を生成するWebシステムが存在しています。例えば、店舗でQRコードを設置して、お客様にアプリのダウンロードを促す施策などで活用されています。そして、そのWebシステムで発行されるURLにアクセスすると、流入数の測定のためにトラッキングデータがBigQueryに格納される仕組みになっています。
弊社では、流入数の測定に Universal Analytics(以下、UAと略記)を利用しており、BigQuery Export で、BigQueryに格納していました。しかし、UAが2024年7月1日に廃止されることが決定されたため、継続的に提供できるように手を打つ必要が出てきました。(ユニバーサル アナリティクスは Google アナリティクス 4 に置き換わりました)
本ブログでは、GA4を利用せずに独自の計測処理を実装する経緯と構築した収集基盤について紹介します。
GA4の利用検討
公式サイトでは、GA4への移行 が推奨されていますが、以下の理由から、GA4を利用せず、独自に計測処理を実装することにしました。
- 金銭的な制約:予算の制約から、GA4の有償版を解約する可能性が高かった
- エクスポートの制約:GA4の無償版では、エクスポートにおいて日次100万件という制約があるため、データ量を考慮すると制約に達してしまう状態だった
- 思想:GA依存させずに、独自の計測処理を入れたいという話が上がっていた
UAで出力されていた中から必要なデータを洗い出す
UAを利用していたこれまでのBigQueryのテーブルには、ga_session.* というテーブル名で日時で作成されていました。そのテーブルには様々な情報が格納されていましたが、機械的に生成された集計には利用していない値もかなり多く含まれていたため、まずは既存データに対して優先度付けを行いました。
弊社では、データを格納する(入力)機構を作るのをエンジニア、格納されたデータを扱う(出力)するのを、データサイエンティストが担当することが多いので、データサイエンティストの方に現在利用しているデータや新規で欲しいデータなどをすり合わせを行いながら進めました。
| 項目 | 意味 | 優先度 | 取得可能か |
|---|---|---|---|
| プロパティA | XXXX | 必須 | ○ |
| プロパティB | YYYY | あると嬉しい | ○ |
| プロパティC | ZZZZ | 不要 | △ |
新収集基盤のシステム設計と構築
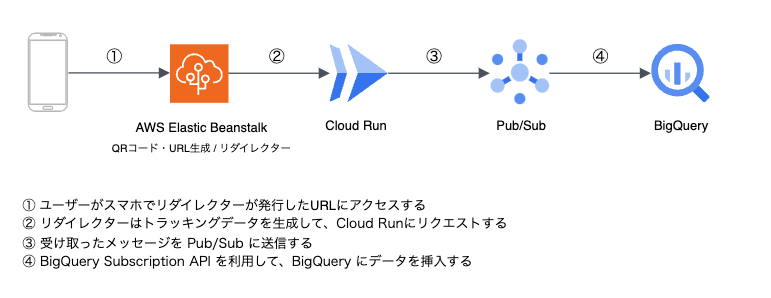
今回は、計測がブラックボックスであった旧基盤(UA)と新基盤の差分がどのくらい出るかという部分がいち早く知りたかった背景もあり、速度を求めた非常にシンプルな構成にしています。流れは以下のようになっています。
※ リダイレクターと記載しているものは、前述した「QRコード(URL)を生成するWebシステム」を指しています。
1)ユーザーがスマホでリダイレクターが発行したURLにアクセスする
ユーザーがスマートフォンで、QRコード・短縮URLを読み込むと、リダイレクターは、そのURLにアクセスしたユーザーを別の指定されたURLに自動的に移動(リダイレクト)させます。例えば、キャンペーンページや商品の詳細ページなどに遷移させます。
2)リダイレクターはトラッキングデータを生成して、Cloud Runにリクエストする
ユーザーのアクセス情報を基に、Webシステムは「トラッキングデータ」を生成します。このトラッキングデータには、ユーザーがどのページにアクセスしたかやの情報が含まれています。こちらのトラッキングデータ生成処理の中で、訪問者IDというユーザー固有のIDを生成しており、多重リクエストがあった際に分析フェーズで弾くことができるようにしています。
上記の訪問者IDのような端末固有のIDは、UAでも存在していましたが、生成方法がブラックボックスだったため仮説で実装しました。今回のプロジェクトでは「自動生成したUUIDを訪問者IDとして、24時間の期限で Cookie に格納する」という方法をとりました。これにより例外を除き(Cookieを保持しない設定など)、複数回のリクエストでも同じユーザーとして識別できるようにしています。
そして、生成したトラッキングデータをBigQueryに挿入するために、Cloud Run にリクエストを送信します。
<?php $visitorId = $_COOKIE[$key] ?? ''; // Cookieに存在しない場合は、新しいIDを生成してCookieに保存 if (empty($visitorId)) { $visitorId = generate(); // UUIDの生成 setcookie($key, $visitorId, [ 'expires' => time() + 60 * 60 * 24, // 24時間 'secure' => true, 'httponly' => true, 'path' => '/', ]); } // リクエスト送信 $url = 'https://xxxxx'; // Cloud Run のエンドポイント $param = json_encode([ 'visitor_id' => $visitorId ]); // visitor_id 以外にも存在しますが、割愛 $ch = curl_init($url); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 3); curl_setopt($ch, CURLOPT_TIMEOUT, 30); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_FAILONERROR, 0); curl_setopt($ch, CURLOPT_POST, true); curl_setopt($ch, CURLOPT_POSTFIELDS, $param); curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); curl_setopt( $ch, CURLOPT_HTTPHEADER, array( 'Content-Type: application/json', 'Content-Length: ' . strlen($param) ) ); $info = curl_getinfo($ch); curl_exec($ch); // リクエストに失敗したらエラーログを出力 if (curl_errno($ch) || $info['http_code'] !== 200) { error_log("Failed to request tracking. HTTP status code: " . $info['http_code']); } curl_close($ch);
3)受け取ったメッセージを Pub/Sub に送信する
CloudRun は受け取ったトラッキングデータを Pub/Sub に送信します。以下のコードは、CloudRun で動かしているアプリケーションコードで、CloudRun で受け取ったデータを Pub/Sub に送信する処理になっています。実際のコードでは責務分けのためにもう少し細かく分かれていたり、バリデーションなども行っていますが、ブログ用にわかりやすく1つのファイルにまとめなおしたサンプルです(挙動確認はできていないのでご容赦ください)。
package main import ( "context" "fmt" "log" "net/http" "os" "cloud.google.com/go/pubsub" ) var ( projectID = os.Getenv("GCP_PROJECT_ID") // 環境変数からGCPプロジェクトIDを取得 topicID = os.Getenv("PUBSUB_TOPIC_ID") // 環境変数からPub/SubトピックIDを取得 ) func main() { http.HandleFunc("/", publishMessageHandler) if err := http.ListenAndServe(":8080", nil); err != nil { log.Fatalf("Failed to start server: %v", err) } } func publishMessageHandler(w http.ResponseWriter, r *http.Request) { ctx := context.Background() switch r.Method { case "POST": client, err := pubsub.NewClient(ctx, projectID) if err != nil { http.Error(w, fmt.Sprintf("Failed to create Pub/Sub client: %v", err), http.StatusInternalServerError) return } // メッセージの内容をリクエストパラメータから取得 message, err := io.ReadAll(r.Body) if err != nil { w.WriteHeader(http.StatusBadRequest) return } defer r.Body.Close() resp := client.Topic(topicID).Publish(ctx, &pubsub.Message{ Data: message, }) // Publishの結果を取得 id, err := resp.Get(ctx) if err != nil { http.Error(w, fmt.Sprintf("Failed to publish message {id: %v}: %v", err), id, http.StatusInternalServerError) return } default: w.WriteHeader(http.StatusMethodNotAllowed) } }
4)BigQuery Subscription API を利用して、BigQueryにトラッキングデータを挿入する
弊社では、これまで Pub/Sub to BigQuery の連携部分は、Dataflow を利用していました。もちろんデータ加工が必要だったので不可欠なのですが、今回の事例だとデータ変換が不要でそのまま扱うことができたので、BigQuery サブスクリプションのユースケースとマッチしました。今後を見越して、Dataflow を立てて間に噛ませることも考えましたが、構築のタイミングで別の機構で利用している Dataflow の SDKバージョンアップ対応などが必要になり、管理コストも発生していた点と、弊社には、BigQuery サブスクリプションの構築事例がなかったため今回は、BigQuery サブスクリプションを採用することにしました。
新旧収集基盤を並行稼働させ、差分検証を実施
検証方法としては、これまで通りダッシュボードの参照先は旧基盤のまま、新基盤ではデータ収集のみを行い、1週間分の BigQuery に蓄積されたデータから差分を検証しました。当初目標は差分5%以内でしたが、無事1%前後に抑えることができました。
Cookie が削除されたり、保持されない場合は訪問者IDが別になるためノイズになることがありますが、かなり近い結果で着地することができました。 またデータの中には、クローラーからのリクエストなども存在していたためそちらは除外するようにしました。また、Android アプリの場合、 1回の読み取りで、2つのリクエストが発生しており、ブラウザからのリクエストとは別に Dalvik という User-Agent が存在していました。こちらも考慮不要のため除外しました。
今後に向けて
計測がブラックボックスだったため、リスクを最小化するためにも仮説検証を短いサイクルで回せるように意識して動きました。また、どうしてもリスクあったため早い段階でのリスク共有を行い進めることができました。今回は速度重視で進めましたが、まだまだ改善の余地はあると思いますので、運用していく中で日々改善したいと思っています。
最後に
ヤプリにご興味がある方いましたら是非カジュアル面談でヤプリ社員と話しませんか?
最後まで読んでいただきありがとうございました!