はじめに
はじめまして!2023年9月に1ヶ月間ヤプリでインターンとして働かせていただきました、北海道大学情報科学院1年生の山田航生 (@koki-algebra) です!私は札幌市に住んでいるのでフルリモートでの業務でした。
大学では機械学習の理論に関する研究をしています。普段は Go や AWS でバックエンドの開発を行うことが多いのですが、今回のインターンではプロダクト開発本部のデータサイエンチームに採用していただきました。
今回インターンに参加したことで、技術的な成長はもちろんのこと、ヤプリとはどのような会社か、ヤプリのデータ活用について理解を深めることができました!
本ブログでは、ヤプリのインターンに参加した経緯、どんな業務に取り組んだのか、インターンにおける学びなどを書いてみたいと思います。
ヤプリのインターンに参加した経緯
私は2023年の3月頃から就職活動を始めました。その頃の私はどちらかというと大手志向であり、いわゆるメガベンチャーと呼ばれる企業群を主な就職先候補として考えておりました。とりあえず学生に人気な企業に就職するのが間違いないだろうと考えていたのです。
そんな私がヤプリの社員の方と初めてお話しすることになったきっかけは、春ごろに行われたとある逆求人イベントでした。そのイベントに参加するまではヤプリという会社を知らなかったですし、ノーコードのアプリプラットフォームについてもそこまで詳しくなかったのです。
逆求人イベントでお話をしたのは2020年にヤプリに新卒入社をされたエンジニアの方で、その年は同期がいなかったそうです。当時正式に新卒採用をしていなかったのにもかかわらず、急成長するヤプリに興味を持って飛び込んでいくその姿勢に私は感動しました。
人事の方が非常に親切だったということもあり、私はヤプリという会社に興味を持つようになりました。そのイベントの後、数回の面談を通して私がどのようなエンジニアになりたいのか、どのようなポジションで働くのが良さそうかをヒアリングしていただきました。
私はバックエンドやインフラが好きで得意だったものの、機械学習に関連する知識も無駄にしたくないという気持ちが強かったため、両方の知識を生かせるポジションを探しておりました。そしてヤプリとの面談を通して、分析用データ基盤を整えるデータエンジニアというポジションが良さそうであるという結論を得ました。
データエンジニアリングに関しては知識が乏しく、実務経験もなかったにもかかわらず、データサイエンスチームでインターンさせていただいたことを非常に感謝しております!
手厚いオンボーディング
ヤプリのインターンはまず研修から始まります。ノーコードプラットフォームの「Yappli」を使って実際にアプリを作ります。この研修は非常に大変で、約300ページにわたる研修資料を読み込みながら、約3日間かけて Yappli のほぼ全ての機能を活用してアプリを作り上げます。大変な一方、Yappli というプロダクトを理解するために非常に重要なステップだと感じました。
さらに、私は「Yappli 勉強会」にも積極的に参加しました。この勉強会を通じて、Yappliがクライアントにどのように提供され、どのように機能が活用されているかを学びました。
普段バックエンド開発に従事していると、ユーザーがアプリをどのように使用しているかを考慮することが疎かになりがちです。しかし、DBモデリングや機能開発の過程で、ビジネス理解が極めて重要です。そのため、プロダクトの洞察を向上させるための研修が充実していることは非常に有益だと感じました。
Yappli Analytics へのクロス集計機能の追加
今回のインターンでは、2023年の3月にリリースしたばかりのアプリデータ分析ツールである Yappli Analytics への機能追加に取り組みました。
Yappli Analytics は Google Cloud BI ツールである Looker Studio を使用して開発されており、アプリ運用に関するトラッキングデータなど、価値のある情報を視覚化する機能を提供しています。このサービスは現在も進化中であり、データに基づいた意思決定をサポートするために、新機能の追加と改善が継続的に行われています。
Yappli Analytics には、フォーム回答の集計機能が組み込まれています。
従来の機能では、フォーム回答の単純な集計に限定され、たとえば性別などの単一の変数に関する情報しか提供されていませんでした。しかし、多くのビジネスシナリオでは、複数の変数が相互に影響を及ぼすことがあります。そのため、クロス集計を導入することで、異なる変数(性別、年齢、地域など)の組み合わせに基づいたデータの視覚化と理解が可能になります。
BigQuery でデータを集計する
フォームデータの集計には、BigQuery内に散在するデータをまとめてデータマートとして集計する必要があります。私は BigQuery のようなデータウェアハウスに触れたことがなかったので、規模の大きいデータに圧倒されてしまいました。まずは BigQuery と仲良くなるところから始めました。
それまではシンプルなCRUD(Create、Read、Update、Delete)処理を行うための簡単な SQL しか触れたことがなかったため、複雑な集計用の SQL を読むことは初めてでした。既存の長大な SQL を理解し、集計に必要なテーブルを把握するのは一苦労でした。
クロス集計をするのに必要なテーブルとビューを把握したら次は実際に SQL を書いていきます。リーダブルSQL[より良いSQLを書くためのシンプルで実践的なテクニック] という記事を参考にして可読性の高い SQL を書くことを心がけました。
SQL も通常のプログラムと同様に上から順に読めるように書くことが重要です。例えば以下の SQL ではデータのインポート処理とフィルタリングなどを行う論理的な操作を分離することで、SQL を上から順に理解しやすくなります。
WITH /* ----- import ----- */ import_table_1 AS ( SELECT * FROM -- ... ), import_table_2 AS ( SELECT * FROM -- ... ), import_table_3 AS ( SELECT * FROM -- ... ) /* ----- logical ----- */ filter_table AS ( SELECT * FROM import_table_1 INNER JOIN import_table_2 -- ... INNER JOIN import_table_3 -- ... WHERE is_active = true ) /* ----- output ----- */ SELECT * FROM `filter_table`;
次にクロス集計用の SQL ですが、こちらは割と単純です。例えば、フォームの質問 question と回答 answer がレコードとして格納されている form_answers というテーブルがあるとします。
このテーブルに対して自己結合を行うことによってクロス集計を行います。
SELECT f1.app_id, f1.question AS question1, f1.answer AS answer1, f2.question AS question2, f2.answer AS answer2 FROM form_answers AS f1 INNER JOIN form_answers AS f2 ON f1.user_id = f2.user_id AND f1.app_id = f2.app_id;
BigQuery で集計が完了すればあとは Looker Studio で図表を作ります。
Looker Studio で図表の作成
Looker Studio は BigQuery などのデータソースとのシームレスな連携が可能です。接続方法などは公式のドキュメントがわかりやすいです。
Looker Studio は複雑なクエリやプログラムの知識がなくても、データにアクセスし、視覚的なレポートや図表を簡単に作成できるようになります。
まずはクロス集計において、どの2つの変数を選んで集計するかを明確にするために、項目ごとの回答数と割合が一目で理解できる図表を作成しました。
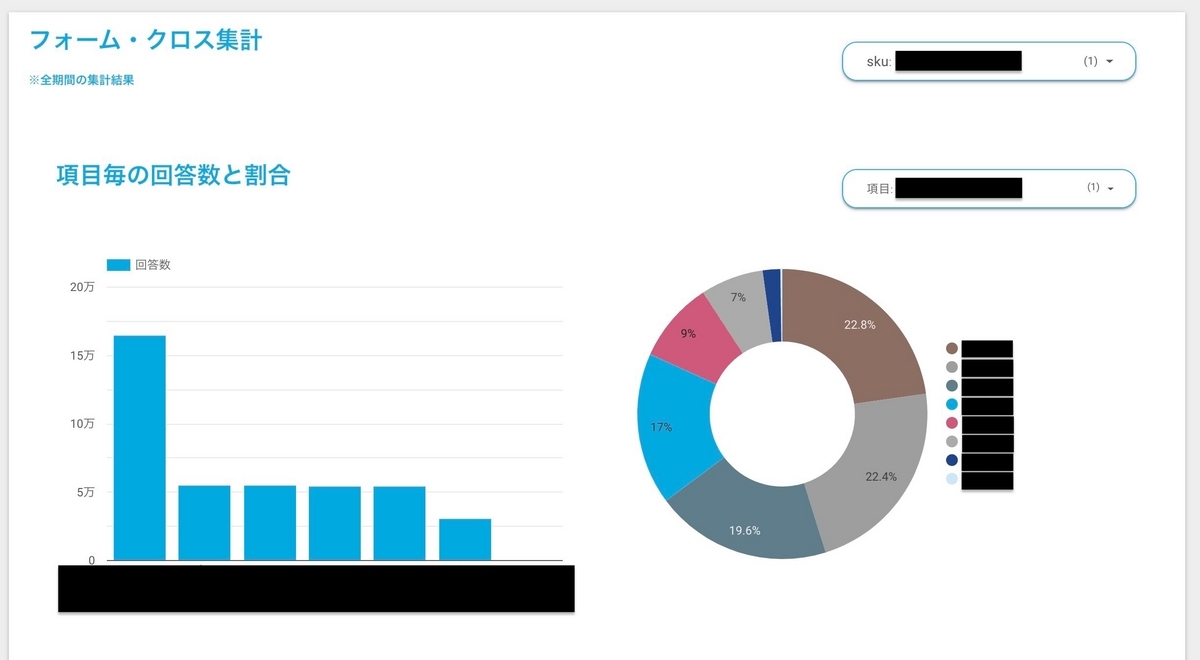
そして、クロス集計を視覚化するのに Looker Studio の「ピボットテーブル」という機能を用いました。このピボットテーブルは、選択した2つの変数の相互関係や重要なパターンをより詳細に探求するための貴重なツールとなります。

今回のインターンに参加する前は、BIツールとは何か全く理解していませんでした。どのようなダッシュボードやレポートが意思決定に役立つのか全くわかりませんでした。しかし、Looker Studioを使用してダッシュボードを作成する経験を通じて、ビジネスインテリジェンスの世界に一歩踏み入れることができました。
はじめてのデータエンジニアリング
私は今回のインターンに参加するまで OLTP (Online Transaction Processing) と OLAP (Online Analytical Processing) の違いを知りませんでした。
OLTP は、日常的な業務トランザクションを処理するために設計されています。これは、データベースに新しいデータを追加、更新、削除するトランザクション処理を指します。主にデータの操作と記録が目的であり、リアルタイムでデータの整合性を維持することが重要です。このようなシステムは今までに開発したことがあり、馴染みのあるものです。
一方 OLAP は、大量のデータから情報を抽出し、分析および報告するために設計されています。主な目的は、データの探索、パターンの発見、トレンドの分析、意思決定支援などです。複雑なクエリや集計が一般的で、データウェアハウス (Data Ware House; DWH) と連携して使われることが多いです。OLAP については馴染みがなく、開発経験もありませんでした。
データエンジニアとは、OLTP で蓄積されたアプリケーションデータベースからデータを抽出 (Extract) し、DWH に抽出したデータをロード (Load) した後、DWH 内でデータを用途に応じて変換 (Transform) する ELT プロセスを設計し、実装するのが主な役割だと認識しています。また、データの効率的なクエリ処理とアクセスを実現し、データ分析の複雑なユースケースに対応するため、DWH の設計とデータモデリングを行うのも重要です。
学生がデータエンジニアリングに興味を持つ機会はなかなか無いと思います。なぜなら個人開発のレベルでは大量のデータが生まれることは滅多になく、データパイプラインを構築するにもクラウドサービスを使うことが多いのでハードルが高いと考えられるからです。
ヤプリは800を超えるアプリを運用しており、トラッキングデータやアクセスログのようなデータが大量に発生しています。このような大規模データに触れる機会は、学生にとって非常に貴重なものであり、データエンジニアとしてのスキルを高める機会となりました。
今回のインターンではデータパイプラインを触る機会はありませんでしたが、dbt やSnowflake などのモダンなデータエンジニアリング技術や、ディメンショナルモデリングなどのデータベースモデリング手法について学び、将来の成長に役立てたいと考えています。
社員の方々と交流
私がインターン参加において、特に重要視しているのは、さまざまな社員とコミュニケーションをとり、会社の雰囲気を理解することです。今回のインターンでは、多くの社員と交流する機会をいただきました!
ヤプリでは「バトンランチ」という文化があり、私が面談を受けた方から他の社員を紹介していただき、それが次々に続く連鎖のようなシステムとなっています。過去のインターンシップでは、主にエンジニアとの面談が中心でしたが、今回はセールスやカスタマーサクセスなどのビジネス職の方々とも交流する機会がありました。
ヤプリの魅力のひとつはエンジニアとビジネス職の距離が近いことだと思っています。明るく友好的な方が多く、部署を超えて気軽に交流できる雰囲気が、私にとって非常に魅力的に感じられました。
さらに、ヤプリは中途採用の方がほとんどを占めていますが、その理由を尋ねてみると、ほとんどの方が Yappli というプロダクトに強い魅力を感じたからだとおっしゃっていました。プロダクトへの愛情が強い社員が多いことも、ヤプリの魅力のひとつだと感じました。
バトンランチを通してヤプリの文化や働き方に深い理解を得ることができました。
まとめ
1ヶ月という短い期間ではありましたが、充実した経験を積むことができました。
- データエンジニアという職種について理解した
- データエンジニアになるために必要な知識を理解した
- BigQuery の使い方を学んだ
- Looker Studio で BI ツールについて学んだ
- ヤプリという会社の文化・社風を知ることができた
- さまざまな職種の方々からキャリアに役立つお話を聞けた
インターン中は自分の成長をなかなか感じられないこともありますが、振り返ってみるとインターンの前後で成長していることがよくわかります。また、インターンに参加して会社の雰囲気や文化を知ることは非常に重要だと思います。
最後に、このインターンに携わっていただいたすべての社員の皆様に心から感謝申し上げます!
ありがとうございました!!