こんにちは。サーバチームの窪田です。 今回は、『A Philosophy of software design』
A Philosophy of Software Design, 2nd Edition: Ousterhout, John: 9781732102217: Amazon.com: Books
で登場する「deep module」という概念の解釈とDDDのRepositoryの設計について考えていきます。
『A Philosophy of software design』について
概要
この本はコンピュータサイエンスのProfessorであるJohn Ousterhout氏
が書いた本で、シンプルなソフトウェアの設計で大切なことがいろいろな視点から述べられています。 冒頭で、complexity(複雑性)を「わかりにくさ+変更しにくさ」と定義し、いかにこの複雑性を除けるかが大事であると書かれています。
Deep Moduleの紹介
『A Philosophy of software design』の1個の強いメッセージとして「ClassはDeep Moduleで設計せよ」というものがあります。 Deep Moduleとは
- 簡単なインターフェイス
- リッチな実装
を兼ね備えるmoduleであると定義されています。
Deep Moduleの例
一例としてUnixのFile I/Oに関わる関数が挙げられています。
int open(const char* path, int flags, mode_t permissions); ssize_t read(int fd, void* buffer, size_t count); ssize_t write(int fd, const void* buffer, size_t count); off_t lseek(int fd, off_t offset, int referencePosition); int close(int fd); The open system call takes
ファイルの読み書きのために使われる関数は直感的でシンプルなインターフェイスを備えています。 例えば、read関数であればどのファイル(int fd)からどの変数(void* buffer)にどのサイズ(size_t count)格納するかというインターフェイスの表現になっています。
一方で、これらの関数は内部的には効率的なファイルアクセス制御の仕組みや割り込みハンドラの制御等の複雑な処理を行なっています。 何百何千行のコードでその処理系は実現されています。
しかし、これらの関数を使う開発者はそれらの複雑な内部処理を意識することなく呼び出すことができます。 これがシンプルなインターフェイスの一番の利点で、開発者の認知負荷を下げ、設計されるソフトウェアの複雑性を低減させます。
Shallow Moduleの例
逆に、インターフェイスが複雑であったり、実装がそこまで厚くないmoduleはShallow Moduleと表現されています。 例として、以下のような関数が挙げられています。
private void addNullValueForAttribute(String attribute) { data.put(attribute, null); }
このような大した機能を持たない関数にたくさん切り分けることで、共通化するメリットよりも認知負荷があがるデメリットが大きくなり、 開発者を困らせることになる、というのが主張です。
DDDにおけるRepositoryの設計を考える
Repositoryの概要
DDDではRepositoryの役割は
- ドメインモデル(のインスタンス)の永続化
- ドメインモデル(のインスタンス)の再構築
です。 Repositoryの実装自体はInfrastructure層に存在し(Repositoryのインターフェイスはdomain層)、 ドメインモデルのインスタンスをデータストアに出し入れする責務を負います。
このRepositoryの設計で今まで自分が見てきた設計を大きく2パターン紹介し、 Deep Moduleの考え方との関わりについて考えていきます。
パターン1: 永続化メソッドを統一するパターン(DDDの本に書いてあるパターン)
DDDの設計でよく例に出てくるRepositoryの設計をまず紹介します。
例えば、ユーザー登録処理とユーザー情報更新という2個のuseCaseを考えてみます。 外部から与えられた名前でユーザーを登録/更新する仕様とします。
まず、User entityは以下のように定義できます。 識別子であるIDとユーザー名をpropertyに持ちます。
package entity type User struct { ID *uint Name string } func NewUser(i *uint, n string) *User { return &User{ ID: i, Name: n, } } func (u *User) ChangeName(n string) error { // 業務ルールに沿ったvalidationがある想定(省略) u.Name = n return nil }
そしてこのUser entityを永続化する役割のUserRepositoryとそのinterfaceは以下のようにかけます。
UserRepositoryの実装↓
// infrastructure層 package repository type UserRepository struct{} func NewRegisterUserRepository() repository_interface.UserRepository { return &UserRepository{} } func (r *UserRepository) Find(id uint) (*entity.User, error) { // data := data store(例えばMySQL)から取得(SELECT id, name FROM users WHERE id = :id;) return &entity.User{ ID: data.ID, Name: data.Name, }, nil } func (r *UserRepository) Save(u *entity.User) error { if u.ID != nil { // dbにupdate処理 (UPDATE users SET name = u.Name WHERE id = u.ID;) } else { // dbにinsert処理 (INSERT INTO users(id, name) VALUES(u.ID, u.Name);) } return nil }
UserRepositoryのinterface↓
// domain層 package repository_interface type UserRepository interface { Save(*entity.User) error Find(id uint) (*entity.User, error) }
これらを組み合わせて、ユーザー登録のuseCaseは以下のようにかけます。
package use_case type RegisterUserUseCase struct { r repository_interface.UserRepository } func (uc *RegisterUserUseCase) Register(n string) error { u := entity.NewUser(nil, n) // data storeの自動発番にIDの採番は任せるためにid: nil err := uc.r.Save(u) if err != nil { return err } return nil }
同様にユーザーネーム更新処理は以下のようにかけます。
package use_case type UpdateUserUseCase struct { r repository_interface.UserRepository } func (uc *RegisterUserUseCase) Update(id uint, n string) error { u, err := uc.r.Find(id) if err != nil { return err } err = u.ChangeName(n) if err != nil { return err } err = uc.r.Save(u) if err != nil { return err } return nil }
ここで、Repositoryの設計についてみてみると、 永続化(Saveメソッド)と再構築(Findメソッド)があるのがわかります。 また、登録するuseCase、更新するuseCaseの両方でSaveメソッドが使われていることもポイントです。 例えばRDB等をデータストアとして採用していた場合、repositoryが内部的に既にDBに存在しているのかをチェックし、 発行するSQL文がINSERT文なのかUPDATE文なのか条件分岐させる必要があります(UPSERT文等で条件分岐を減らせる部分はあるが、本質的には条件分岐が必要)。
反面、useCase側ではrepositoryをとても使いやすくなります。 データストアの状態に関わらず、User entityのインスタンスを永続化したいときはSaveメソッドを使っておけば良いからです。 INSERT文とUPDATE文のどちらが流れるかみたいなことを意識しなくて良くなる大きなメリットがあります。
一方で、永続化する集約が大きくなるとRepositoryのSaveメソッドの実装がかなり大変になるというデメリットがあります。 例えば、ユーザー名変更するたびに変更履歴を残したいとなったとします。
entityとしてはUser entityとChangeNameHistory entityが登場します。 このUserモデルと名前変更モデルの整合性を強く取りたい場合、同じ集約として(ここではUser集約)まとまることになります。
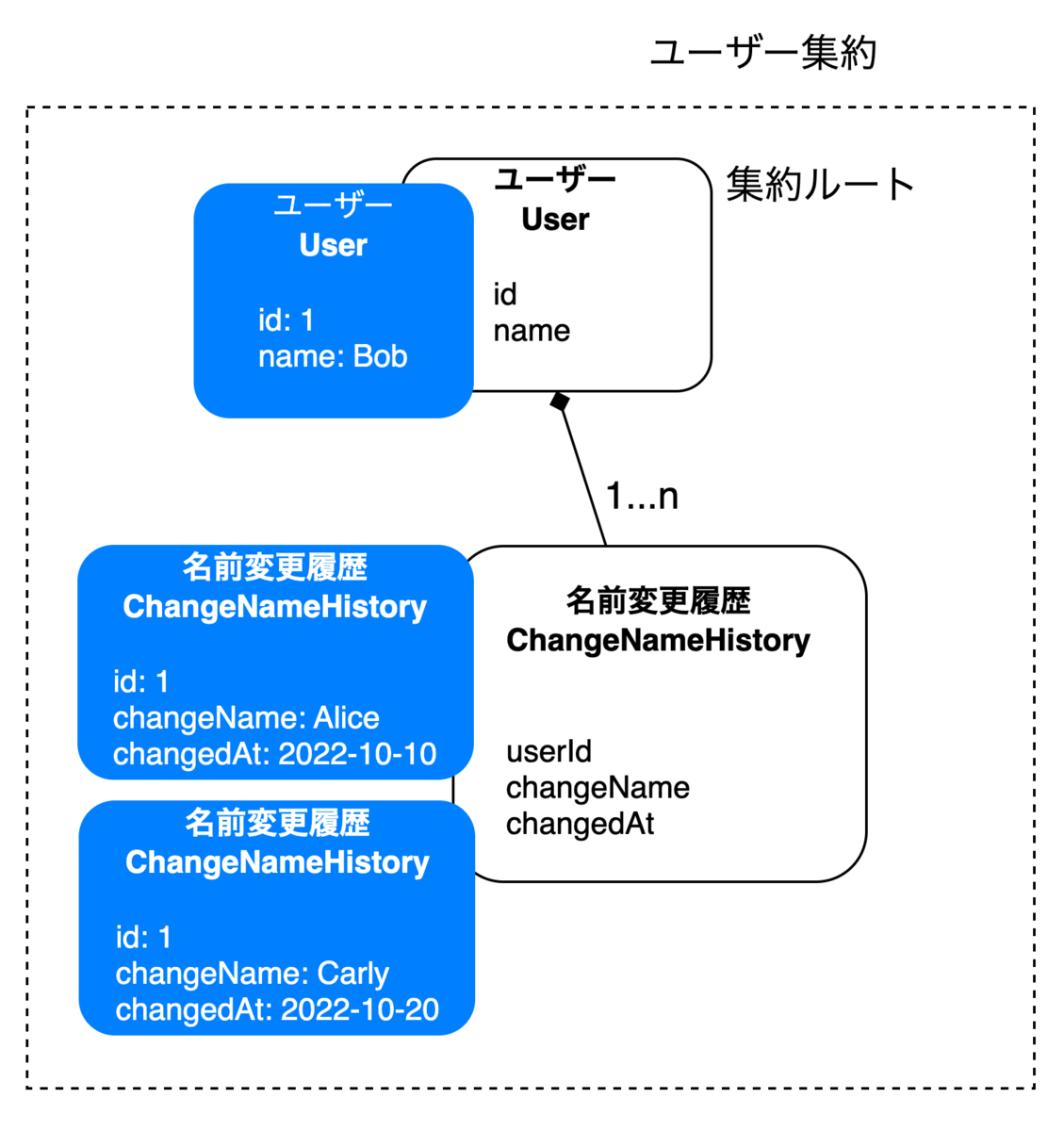
この集約設計をした場合、実装上は以下のようにUser entityがChangeHistory entityのsliceを持つようになります。
package entity type User struct { ID *uint Name string ChangeHistories []*ChangeHistory } type ChangeHistory struct { UserID uint ChangeName string ChangedAt time.Time }
これに対応したSaveメソッドは以下のようになります。
func (r *UserRepository) Save(u *entity.User) error { if u.ID != nil { // users tableにupdate処理 (UPDATE users SET name = u.Name WHERE id = u.ID;) histories := // dbに存在するhistoryを取得(SELECT * FROM change_name_histories WHERE user_id = u.ID;) for _, h := range u.ChangeNameHistories { for _, eh := range histories { // 既にdbに存在すれば何もしない if h.ChangedAt == eh.ChangedAt { continue } // 存在しなければinsert // change_name_histories tableにinsert処理(INSERT INTO change_name_histories(user_id, name, changed_at) VALUES(u.ID, u.Name, h.ChangedAT);) } } } else { // dbにinsert処理 (INSERT INTO users(id, name) VALUES(u.ID, u.Name);) } return nil }
かなり露骨に書いていますが、Repositoryの実装が複雑化するのがわかると思います。 プロダクションコードになると、entityに定義されるpropertyももっと多く、集約も大きくなる場合はよくあります。 SQLのパフォーマンス等も考え出すとSaveメソッドの中はかなり複雑になり、テストを書くのも辛くなることが想定されます。(そういう事例を見たことがあります)。
パターン2: 永続化メソッドを分割するパターン
Saveメソッドが複雑化しすぎたと判断した場合、Saveメソッドを分割する場合があります。 例えば、先ほど出したユーザー登録/更新の2つのuseCaseで使うRepositoryのメソッドを別々に定義することができます。
Repositoryのインターフェイスと実装はそれぞれ以下のようになります。
UserRepositoryの実装↓
// infrastructure層 package repository type UserRepository struct{} func (r *UserRepository) Find(id uint) (*entity.User, error) { // data := data store(例えばMySQL)から取得(SELECT id, name FROM users WHERE id = :id;) return &entity.User{ ID: data.ID, Name: data.Name, }, nil } func (r *UserRepository) Register(u *entity.User) error { // dbにinsert処理 (INSERT INTO users(id, name) VALUES(u.ID, u.Name);) return nil } func (r *UserRepository) Update(u *entity.User) error { // dbにupdate処理 (UPDATE users SET name = u.Name WHERE id = u.ID;) return nil }
UserRepositoryのinterface↓
// domain層 package repository_interface type UserRepository interface { Register(*entity.User) error Update(*entity.User) error Find(id uint) (*entity.User, error) }
このように登録と更新をRepositoryの別メソッドとして定義する場合、パターン1のような分岐は減ります。 一方でデメリットもあります。 インターフェイスをみるとよくわかりますが、このパターンでは永続化メソッドが2個存在します。 useCaseでentityを永続化する際にその都度どのメソッドを使うのかを判断して実装する必要があります。
Deep Moduleとの関わり
Deep Moduleの考え方は実はパターン1に対応します。 Repositoryの実装自体は複雑になりますが、インターフェイスはSaveメソッドだけでとてもシンプルになります。 これにより外部(例えばuseCase)から使う場合何も考えずに永続化するときはSaveメソッドを使えば良いという状態を作れます。 これが、『A Philosophy of software design』で述べられている認知負荷を減らすことに対応し、総合的に見たプロダクトの複雑性は低減することができます。
一方で、パターン2はShallow Moduleに対応します。 実装自体は薄くなる反面、インターフェイスが複雑化しuseCase実装者からすれば認知負荷が上がるということになります。
まとめると以下です。
- 永続化メソッドをSaveに統一
- pros
- Deep Moduleを実現している
- インターフェイスがシンプル
- useCase実装者の認知負荷が下がる
- cons
- 扱う集約が大きいorドメインモデルが大きい(propertyが多い)ときにRepositoryの実装が肥大化する。
- その場合テストが書きにくい
- pros
- 永続化メソッドを分割
- pros
- テストが書きやすい
- 初見の人が読みやすい
- cons
- Shallow Moduleになってしまう
- インターフェイスが複雑化する
- useCase実装者の認知負荷が上がる(どの永続化メソッドを使えば良いか意識しなくてはいけない->結局repositoryの実装の中身を見にいくことになる)
- pros
個人的考え
『A Philosophy of software design』を読んでからはSaveに統一することに大きな意義を感じています。 もし、新規プロダクトの設計を0からやるのであればDeep Moduleを意識したパターン1の設計をすると思います。 一方で、Deep Moduleが強い効果を発するのは変更が少ないModule設計に限定されるとも感じているため、 例えばinfrastructure層といいながらも高頻度で修正が入るような開発プロダクトについては、多少の分割は許容して良いと思います。
特にRegisterとUpdateを分割すること自体は認知負荷をそこまで上げる気はしていません。(人間はCRUDを体系的に知っているし、ある程度自然な考え方だと思っています)。 これが、同じ集約のentityを複数メソッドで永続化し始めてしまうようなアンチパターンさえ避けられれば有効な手段だとも思う今日この頃です。
考えるきっかけ
そもそも『A Philosophy of software design』を読んだきっかけは社内の技術共有会の中で技術書LT(読んだ技術書をチームのメンバーに紹介するコーナー)があったことでした。 色々なエンジニアが色々な本を紹介しあって楽しい場になっています。 iOS, Androidエンジニア, フロントエンドエンジニア、サーバーサイドエンジニア、SRE、データサイエンティストが集まっている中で技術共有ができる文化があるのは面白いです。 興味を持たれた方はカジュアル面談で是非お話しましょう!!